表引擎
表引擎即表的类型,决定了数据的组织和存储方式、索引的方式以及索引类型、支持哪些查询以及如何支持和一些其他特定的功能和配置 ByConity 里最常用的表引擎是有三种: CnchMergeTree、CnchKafka、CnchMaterializedMySql 。下面重点讲下这三种表引擎的原理。
CnchMergeTree 表引擎
实现原理
CnchMergeTree 表是最常用的表引擎,核心思想和 LSM-Tree 类似,数据按分区键(partition by)进行分区,然后排序键(order by)进行有序存储。主要特点:
- 逻辑分区 (Partition)
如果指定了分区键的话,数据会按分区键划分成了不同的逻辑数据集(逻辑分区,Partition),每一个逻辑分区可以存在零到多个数据片段(DataPart)。如果查询条件可以裁剪分区,通常可以加速查询。如果没有指定分区键,全部数据都在一个逻辑分区里。
- 数据片段 (Fragment)
数据片段里的数据按排序键排序。每个数据片段还会存在一个 min/max 索引,来加速分区选择。
- 数据颗粒(Granule)
每个数据片段被逻辑的分割成颗粒(Granule ),默认的 Granule 为 8192 行(由表的 index_granularity 配置决定)。颗粒是 ByConity 中进行数据查询时的最小不可分割数据集。每个颗粒的第一行通过该行的主键值进行标记, ByConity 会为每个数据片段创建一个索引文件来存储这些标记。对于每列,无论它是否包含在主键当中,ByConity 都会存储类似标记。这些标记让您可以在列文件中直接找到数据。Granule 作为 ByConity 稀疏索引的索引目标,也是在内存中进行数据扫描的最小单位。
- 后台 Merge
后台任务会定时对同一个分区的 DataPart 进行合并,并保持按排序键有序。后台的合并减少了 Part 的数目,以便更高效存储,并提升了查询性能。
建表语句和相关配置
CREATE TABLE [IF NOT EXISTS] [db.]table_name
(
name1 [type1] [NULL|NOT NULL] [DEFAULT|ALIAS expr1] [compression_codec] [TTL expr1],
name2 [type2] [NULL|NOT NULL] [DEFAULT|ALIAS expr2] [compression_codec] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2,
) ENGINE = CnchMergeTree()
ORDER BY expr
[PARTITION BY expr]
[CLUSTER BY (column, expression, ...) INTO value1 BUCKETS SPLIT_NUMBER value2 WITH_RANGE]
[PRIMARY KEY expr]
[UNIQUE KEY expr]
[SAMPLE BY expr]
[TTL expr]
[SETTINGS name=value, ...]
设计分区键(PARTITION BY)
分区键定义分区,分区是在一个表中通过指定的规则划分而成的逻辑数据集。可以按任意标准进行分区,如按日期。为了减少需要操作的数据,每个分区都是分开存储的。查询时,ByConity 尽量使用这些分区的最小子集。建表时候通过 PARTITION BY expr 子句指定。分区键可以是表中列的任意表达式。例如,指定按月分区,表达式为 toYYYYMM(date);或者按表达元组,如 (toMonday(date), EventType) 等。
需要注意,表中分区表达式计算出的取值范围不能太大(推荐不超过一万),太多分区会占用比较大的内存以及带来比较多的 IO 和计算开销。
合理的设计分区键可以极大减少查询时需要扫描的数据量,一般考虑将查询中最常用的条件同时取值范围不超过一万的列设计为分区键(如日期等)。
设计排序键(ORDER BY)
可以是一组列的元组或任意的表达式。 例如: ORDER BY (OrderID, Date) 。
如果不需要排序,可以使用 ORDER BY tuple()。DataPart 里的数据将按照排序键进行排序。请注意,order by 使用的字段在建表后,无法被修改。
设计主键(PRIMARY KEY)
默认情况不需要显式指定,ByConity 将使用排序键作为主键。当有特殊场景主键和排序键不一致时,主键必须为排序键的最左前缀。如排序键为(OrderID, Date),主键必须为 OrderID,不能为 Date。在一些特殊的表引擎,如 CnchAggregatingMergeTree、CnchSummingMergeTree 中,主键会与排序键不同。
ByConity 会在主键上建立以 Granule 为单位的稀疏索引,(与之对比,所谓稠密索引则是每一行都会建立索引信息)。
如果查询条件能匹配主键索引的最左前缀,通过主键索引可以快速过滤出可能需要读取的数据颗粒,相比扫描整个 DataPart,通常要高效很多。
另外需要注意,PRIMARY KEY 不能保证唯一性,所以可以插入主键重复的数据行。
分区(PARTITION BY)和主键(PRIMARY KEY)是两种不同的加速数据查询的方式,定义的时候应当尽量错开使用不同的列来定义两者,来覆盖更多的查询场景。例如 order by 的第一个列一定不要重复放到 partition by 里。下面是如何选择主键的一些考虑:
- 是否是查询条件里常用的列
- 不是非分区键的第一个列
- 这个列的选择性,例如性别、是/否这种可选值太少的列不建议放入主键中
- 假如现在的主键是(a,b),如果在大多数情况下给定(a,b)对应的数据范围很大(包含多个 Granule),可以考虑把一个新的查询常用列附加到主键中,这样可以过滤更多的数据。
- 过长的主键会对插入性能和内存消耗有负面影响,但对查询性能没有影响。
设计唯一键(UNIQUE KEY)
主键(PRIMARY KEY)不能保证去重,如果有唯一键去重的需求,需要在建表时设置唯一键索引。设置唯一键之后,ByConity 提供 upsert 更新写语义,可以根据唯一键高效更新数据行。查询自动返回每个唯一键的最新值。
唯一键可以是一组列的元组或任意的表达式,如 UNIQUE KEY (product_id, sipHash64(city))。
唯一建索引可以通过配置 partition_level_unique_keys 控制是分区级别唯一还是全表唯一,目前推荐实践为:分区唯一索引,单分区数据量不超过千万级别。若为全表唯一,则全表数据量建议不超过千万级别。
通过唯一键查询时会用上唯一键索引过滤数据加速查询,所以通常主键可以设置和唯一键不一样列,覆盖更多的查询条件。不过如果要使用部分列更新功能的话,是需要唯一键为排序键的最左前缀。
- 相关配置
partition_level_unique_keys- 唯一索引是否是分区唯一,默认值:true;如果为false,代表唯一索引是全表级别;cloud_enable_staging_area- 是否开启异步写入模式,默认值:false。
Granule 配置
index_granularity— 索引粒度。索引中相邻的『标记』间的数据行数(对应 Granule 大小)。默认值 8192 。
后面三个配置待测试,RD 未验证功能。
index_granularity_bytes— 索引粒度,以字节为单位,默认值: 10Mb。如果想要仅按数据行数限制索引粒度, 请设置为 0(不建议)。min_index_granularity_bytes- 允许的最小数据粒度,默认值:1024b。该选项用于防止误操作,添加了一个非常低索引粒度的表。enable_mixed_granularity_parts— 是否启用通过index_granularity_bytes控制索引粒度的大小。在老版本只有index_granularity配置能够用于限制索引粒度的大小。当从具有很大的行(几十上百兆字节)的表中查询数据时候,index_granularity_bytes配置能够提升 ByConity 的性能。如果您的表里有很大的行,可以开启这项配置来提升SELECT查询的性能。
列和表的 TTL
指定行存储的持续时间并定义数据片段在硬盘和卷上的移动逻辑的规则列表,可选项。
表达式中必须存在至少一个 Date 或 DateTime 类型的列,比如:
TTL date + INTERVAl 1 DAY
更多细节,请查看 表和列的 TTL
最佳实践
- 主键索引的最佳实践
https://clickhouse.com/docs/zh/guides/improving-query-performance/sparse-primary-indexes/
- 二级索引最佳实践
https://clickhouse.com/docs/zh/guides/improving-query-performance/skipping-indexes
- 列类型考虑
避免一味使用 String 类型
如果可能的情况下使用 Int(8|16|32|64|128|256) / Date / Date32 / DateTime / DateTime64 / Float / Decimal 代替 String
最简单的判断方法就是看是否可以转换到目标类型比如 SELECT countIf(toUInt8OrNull(col) IS NULL) FROM table, SELECT countIf(toDateOrNull(col) IS NULL) FROM table
对内容相对固定的 String Column, 可以考虑使用 Enum 代替,比如省份名称. Enum 后期可以通过 ALTER TABLE 添加新值
String 最小最大长度差距不超过 8 的情况下使用 FixedString,因为 String 相比 FixedString 在内存中要多储存 8 字节的 offset SELECT min(length(col)), max(length(col)) FROM table
- Nullable 选择
如果确定列中不包含 Null,不要使用 Nullable 类型,会对性能有负面影响
- LowCardinality
如果某个列的基数较低,例如一个 DataPart 内只有不超过 10000 个不相等的值,可以考虑用 LowCardinality 类型。LowCardinality 类型会对原始列进行字典编码。对很多应用来说,处理字典编码的数据可以显著的增加查询速度,并且降低存储空间,提升 IO 效率。
- 参考文档
https://clickhouse.com/docs/en/sql-reference/statements/create/table/#column-compression-codecs
CnchKafka 表引擎
功能定义
CnchKafka 是 ByConity 基于社区 ClickHouse Kafka 表引擎自研实现的适配云原生架构的表引擎,用于高效快速地将用户数据从 Apache Kafka 实时导入 ByConity;其设计与实现既适配了云原生新架构,同时在社区实现基础上增强了部分功能。
CnchKafka 主要功能特点包括:
- 提供基于云原生架构优势的自动容错能力,降低运维成本。
- 可扩展的消费能力:支持通过 SYSTEM 命令调节消费者数目,最高适配 topic 对应的 partition 数。
- 增强消费语义:依赖 Transaction 保证,通过引擎管理 offset 实现 Exactly-Once 消费语义。
- 消费性能:很大程度依赖用户表的 schema 复杂度,通常经验值 2k-2M 条/秒,吞吐 15MiB/s 左右。
- 支持多种数据类型,包括但不限于 Json、ProtoBuf、CSV 等。
- 支持记录消费日志,既方便排查问题,也提供了数据审计的能力。
实现原理
CnchKafka 继承了社区的基本设计,即通过一个 <CnchKafka 消费表、Materialized View 物化视图表、存储表 > 三元组实现整个消费链路,其中:
- CnchKafka 消费表:负责订阅 Kafka topic 并消费消息;将得到的消息解析后写为 Block。
- Materialized View 物化视图表:构建从消费表到存储表的数据通路,将 CnchKafka 消费的 Block 写入存储表,并提供简单的过滤功能。
- 存储表:支持 Cnch 多种 MergeTree 存储表。
基本数据通路如下:
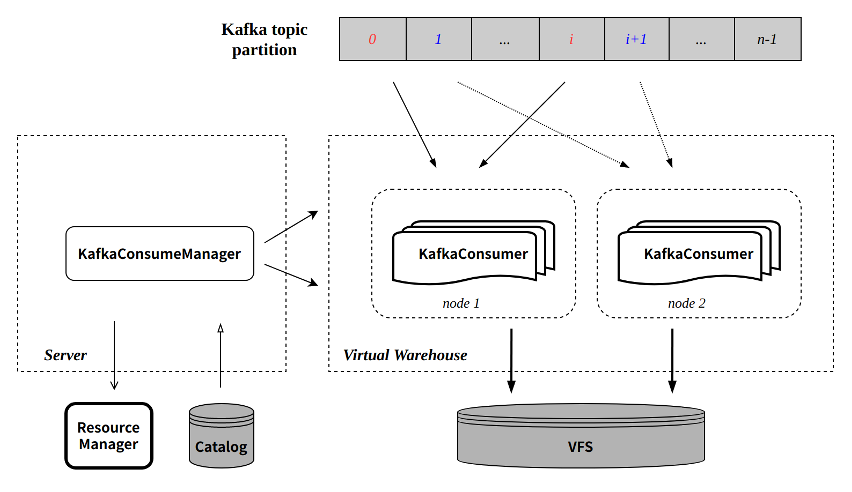
组件说明
Server
应用接入层,所有查询和导入任务的入口;轻量级设计,本身不做具体查询和导入,主要负责任务调度转发和元数据访问,包括:
- 预处理查询请求,从 Catalog 读取元数据,将原数据和查询 sql 下发查询节点,将查询结果返回上层(调用接口或用户等)。
- 管理导入任务:选择导入节点执行导入任务。
- 和 Catalog 交互,查询或更新元数据。
- 和 Resource Manager 交互,选择任务执行节点保证负载均衡。
Virtual WareHouse
- 计算层,所有查询和导入任务的执行节点,无状态服务;
- 支持租户独享,实现资源和数据隔离;
- 支持读写分离,查询和导入可创建和指定不同 Virtual WareHouse。
Catalog
- KV 数据库,用于元数据管理,包括数据库表元信息、part 元信息等;
- CnchKafka 消费 offset 也存储在 catalog。
VFS
- 底层存储,支持多种存储系统,包括 HDFS、S3 等。
KafkaConsumeManager
每张 CnchKafka 消费表会在 Server 层启动一个 Manager 负责调度和管理所有的消费者任务。Manager 本身是 Server 端的一个常驻线程,通过 Server 的高可用和 DaemonManager 保证其服务稳定。 KafkaConsumeManager 主要实现和功能包括:
- 根据配置的 consumer 数目将 topic partition 均匀分发到每个 consumer。
- 与 Catalog 交互,获取 partition 消费的 offset。
- 调度 consumer 到配置的 Virtual Warehouse 节点执行:节点选择支持多种策略配置,保证负载均衡。
- 定期探活每个 consumer 任务,保证任务执行的稳定性。
KafkaConsumer
每个 KafkaConsumer 实现为一个常驻线程在 Virtual Warehouse 节点执行,负责从指定的 topic partition 消费数据,转换为 part 写入 VFS,并将元信息提交回 Server 端写入 Catalog。主要特点:
- 继承社区的攒批写入模式(每次消费周期默认 8 秒)。
- 每次消费过程通过 Transaction 保证原子性:通过与 Server RPC 交互创建事务;事务提交会同时提交写入的 part 元信息以及最新消费的 offset。单次消费执行流程可参考下图
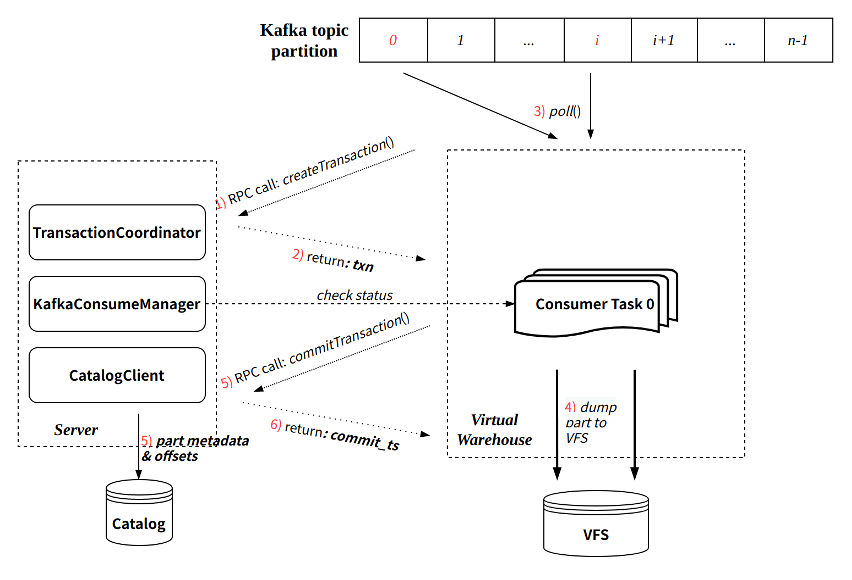
Exactly-Once
与社区实现相比,CnchKafka 实现增强了消费语义,即从社区的 At-Least-Once 语义,升级为 Exactly-Once 语义。这主要得益于新架构 Transaction 事务的保证。由于每轮消费都会通过事务管理,且每次提交数据元信息的同时提交对应的 offset。由于事务保证了提交的原子性,那么数据元信息和 offset 要么同时提交成功,要么都提交失败。这样就保证了数据和 offset 始终一致,每次消费重启都从上次提交的 offset 位置继续消费,从而实现了 Exactly-Once。
自动容错实现
CnchKafka 整体容错策略采取快速失败方式,即:
- KafkaConsumeManager 定期探活 consumer 任务,探活失败,立即拉起一个新的 consumer;
- KafkaConsumer 每次执行中,与 Server RPC 的两次交互(创建事务和提交事务)都会向 Manager 校验自身的有效性,如果校验失败(比如 Manager 已经拉起了一个新的 consumer 等),会主动 kill 自己。
设计 Bucket 表
Bucket 表是一个可选的表级设置,如果设置合适的 Bucket, 系统会根据用户提交的 Cluster Key(即建表语句中提供的一个或者多个列、表达式)去整理表数据,将相同值的数据聚簇在同一个 bucket number 下。
使用 Cluster Key 聚簇数据在大表上可以获得以下几项收益:
- 针对 cluster key 的点查可以过滤掉大部分数据,降低 IO 量获得更短的执行时间和更高的并发 QPS;
- 针对 cluster key 的聚合计算,可以有更少的内存占用和更短的执行时间,配合 distributed_perfect_shard 优化可以获得进一步的提高;
- 两张或者多张表针对 cluster key 的 join 可以获得 co-located join 的优化,极大的降低 shuffle 数据量并得到更短的执行时间;
由于 Bucket 表的设置比较复杂,一般情况下有两种场景适合设置:
- 表足够大,意味着在一个分区下的 parts 数量至少需要显著多于 worker 数量;
- 查询语句可以从上述收益点中获益;
如何选择 cluster key
Cluster key 可以是一个或者多个列、表达式,建议最多使用 3 个字段,更多的字段通常会引入过高的写入代价且获益语句范围更小。
选择正确的 cluster key 对于性能的影响非常显著,因此需要慎重选择。通常可以按照如下原则:
- 经常用于相等、IN 过滤的列
- 常用的聚合列
- 多表的 join key
上述场景如果常用的情况是两列组合,比如 a = 1 and b = 2,那么 cluster key 选择两列可以获得更好的效果。
另一个需要考虑的维度是列的 distinct 值数量,鉴于
- 相同 cluster key 的数据会归属于同一个 bucket number
- 一个 bucket number 下的所有 parts 会发送到同一个 worker 中进行计算
我们可以得出结论
- 为了能利用所有 worker 节点进行计算,distinct 值需要至少超过 worker 数量
- 如果 distinct 值数量较小,偏向于选择最大的 distinct 值,最好为 worker 数量的倍数,以实现查询时数据分布的更均衡
例如:
- 表 test,用户常用的过滤列是 c1, c2, c3,列相互独立
- worker 数量为 30
- distinct c1 为 6
- distinct c2 为 8
- distinct c3 为 5
可以看出 3 中单独的 distinct 都小于 worker 数量。disticnt c1, c2 为 48 虽然大于 worker 数量,但是不是 worker 数量的倍数,因此也不是合适的 cluster key。distinct c1, c3 为 30 正好为 worker 数量的 1 倍,但考虑数据分布的均衡性,选择更大的 distinct c1, c2, c3 为 8 倍 worker 数量更为合适
如何选择 bucket number
鉴于在一个分区内
- 每行数据会依据 cluster key 的值按
% BUCKETS计算得到相应 bucket number - 同一个 bucket number 的 parts 在查询时会发送到同一个 worker 节点上计算
因此选择一个合适的 bucket number 对于存储和查询都有重大的影响,一般有如下原则:
- 确保 bucket number 为 worker 数量的倍数,这是为了保证查询时分配的均衡,一般建议设置为 1 倍或者 2 倍(预留扩充 worker 节点余度)worker 节点数量即可
- 确保一个分区下一个 bucket number 中有足够多的数据,不要生成太小的 parts,因此建议如果表比较小,至少确保一个分区的一个 bucket number parts 大小超过 1GB。不要设置过高的 bucket nubmer,可以出现小于 worker 数量的 bucket number
如何决定是否要修改 cluster by 定义
在运行过程中因为数据变化、查询模式变化、worker 节点数量变化,用户可能会想要重新设置 cluster key 和 bucket number。
这里需要考虑实施修改的代价,权衡是否需要修改已经何时修改:
- 修改 cluster by 定义需要对现存已有数据做 recluster,需要评估现存数据量估算 recluster 执行时间
- recluster 期间现存数据的查询会回退为一张普通表,所有 bucket table 的收益暂时都失去
- Recluster 会占用 write worker 的资源,需要评估当前 cnch 集群是否有独立的 write worker 以及当前负担,评估对现有查询、merge 等任务的影响
有两种修改 cluster by 定义的情况:
- 修改 cluster key
- 此时意味着当前的数据已经无法获得 bucket table 收益,因此无需考虑 recluster 期间失去的收益
- 需要评估 recluster 任务对于现有任务的影响判断是否可以执行
- 修改 bucket number
- 当前 bucket table 的收益仍在,因此需要和业务方确认可以接受的性能回退的时间,进一步根据 recluster 时间判断是否可以执行,以及确定开始执行时间
- 也需要评估 recluster 任务对于现有任务的影响判断是否可以执行