主要原理概念
简介
ByConity 的查询执行流程如下图所示,首先通过元数据服务获取查询所需要的元数据信息,然后根据用户 sql 通过优化器生成高效的查询计划,并调度到相应的计算组上去读取数据并执行,最终进行结果集的汇总并发送回客户端。为了用户更好的了解 ByConity 查询的工作原理,此章会介绍 ByConity 的主要原理。
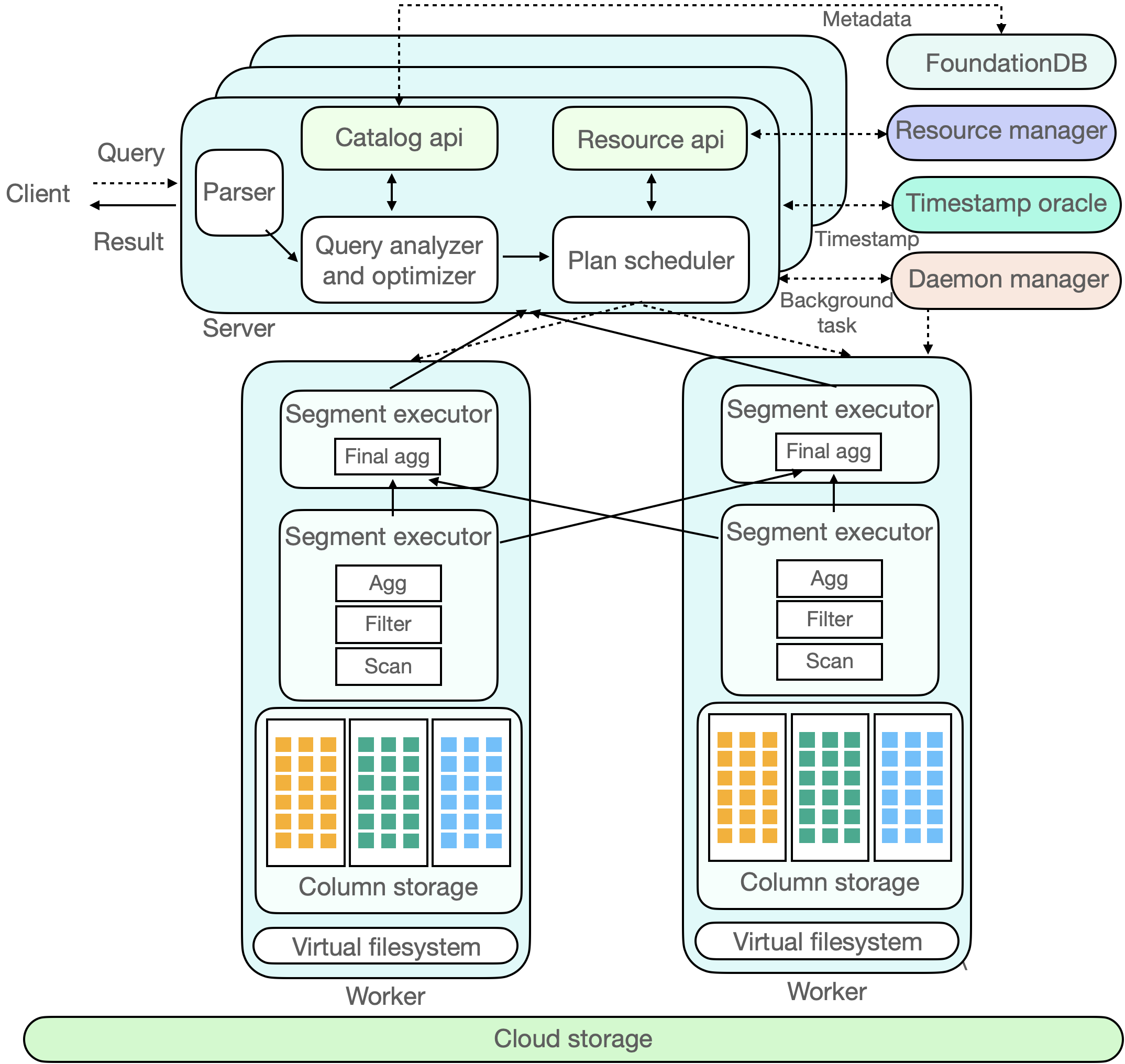
元数据管理(Catalog Service)
元数据管理(Catalog Service)的功能主要是对读写请求的元数据进行读写操作。元数据服务是一个非常关键的服务,其决定了查询的可用性和正确性。在 ByConity 里,我们不仅提供了高可用,可扩展的元数据管理服务,还在其之上实现了完备的事务语义保证(ACID)。除此之外,ByConity 还借助缓存,对查询涉及到的原数据提供低延迟读取,保证查询性能高效稳定。
查询优化器(Query Optimizer)
优化器(Query Optimizer) 是数据库系统的核心之一,优秀的优化器能极大提高查询性能,特别是在复杂查询场景下优化器能带来数倍至数百倍的性能提升。
ByConity 自研优化器基于四个大的优化方向提供极致优化能力:
- RBO:基于规则的优化能力。支持:列裁剪、分区裁剪、表达式简化、子查询解关联、谓词下推、冗余算子消除、Outer-JOIN 转 INNER-JOIN、算子下推存储、分布式算子拆分等常见的启发式优化能力。
- CBO:基于代价的优化能力。支持:Join Reorder、Outer-Join Reorder、Join/Agg Reorder、CTE、物化视图、Dynamic Filter 下推、Magic Set 等基于代价的优化能力。并且面向分布式计划融合了 Property Enforcement。
- DBO:基于数据依赖的优化能力。支持:唯一键、functional dependency、Order dependency、Inclusion dependency 等基于数据依赖关系的优化能力。
- HBO:基于查询反馈的优化能力。支持:基数估计动态调整、并行度动态调整、执行计划动态调整等基于历史执行反馈的优化能力。
计算组(Virtual Warehouse)
计算组(Virtual Warehouse: 简称 VW) 是计算资源的虚拟组织,可以将计算资源按需划分为多个虚拟集群,在不同租户之间提供物理资源隔离。每个虚拟集群里包含 0 到多台计算节点,按照实际资源需求进行动态扩缩容。
计算资源扩缩容的方式有两种:
- 一种是纵向扩容,即调整计算组的 CPU 核数和内存大小;
- 另一种是横向扩容,增减计算组的数量,提升系统并发能力;
在存储计算分离的架构下,计算资源与存储资源是解耦的且无状态的,扩缩容过程不需要迁移和平衡数据,因而可以实现快速弹性扩缩容。
计算节点主要承担的是计算任务,这些任务可以是数据写入、用户查询,也可以是一些后台任务。在 ByConity 存储分离架构下,用户查询可以实现读写分离,降低读写作业之间的互相干扰。用户查询和后台任务,可以共享相同的计算节点以提高利用率,也可以使用独立的计算节点以保证严格的资源隔离。用户可以根据计算任务的特性、优先级和业务类别不同,构建多个计算组,并设置不同的资源弹性策略,提高计算效率降低成本。
虚拟文件系统(Virtual File System-VFS)
ByConity 采用 HDFS 或 S3 等云存储服务作为数据存储层,用来存储实际数据、索引等内容。数据表的数据文件存储在远端的统一分布式存储系统中,与计算节点分离开来。底层存储系统可能会对应不同类型的分布式系统。例如 HDFS,Amazon S3, Google cloud storage,Azure blob storage,阿里云对象存储等等。
不同的分布式存储系统,有很多不同的功能和不一样的性能,会影响到功能的设计和实现。例如 hdfs 不支持文件的 update, S3 object move 操作时重操作需要复制数据等。ByConity 通过存储的服务化,对计算层提供统一的抽象文件系统接口,存储层采用 S3 还是 HDFS 对计算层透明;计算层可以支持 ByConity 自身的计算引擎之外,将来还可以便捷地对接其他计算引擎,例如 Presto、Spark 等。
列式存储(Columnar Storage)
与主流分析数据类似,ByConity 采用列式存储格式,减少不必要的数据 IO 提高查询性能,并对数据进行高效压缩,降低存储成本。除此之外,对于连续存储的列式数据,ByConity 通过向量化执行技术,进一步提升查询性能。
主要流程
查询执行
- 用户提交 Select Query 到服务节点;
- 从元数据服务获取需要的元数据信息,对 Query 进行 Parsing,Planning,Optimising,生成执行计划;
- 服务节点根据可用的计算资源对执行计划进行调度,发送任务到计算节点;
- 计算节点接收到 Query 子查询;
- Query 从虚拟文件系统(VFS) 获取数据,并根据 Query 的执行计划在计算节点上执行,并发回计算结果给服务节点汇总;
数据写入
- 用户提交 Write Query 到服务节点;
- 服务节点对写入请求根据调度策略选择合适的写入节点执行;
- 写入节点执行写入,将数据写到本地盘并 dump 到云存储端;
- 提交 part 元数据到元数据服务(Catalog Service),提交事务,写入完成;
计算组扩缩容
资源管理器(Resource Manager)负责对计算资源进行统一的管理和调度,能够收集各个计算组的性能数据,资源使用量,为读写任务和后台任务动态分配资源并进行扩缩容,提高资源使用率。ByConity 的组件都已经容器化,通过调整 kubernets 的 replica 数量可以非常方便的对指定的计算组进行扩缩容。除此之外,还可以结合计算组资源使用量,通过设置 kubernets 的扩缩容阈值实现动态扩缩容。