Monitor Cluster
Common Monitoring Indicators
Prometheus Monitoring Indicators:
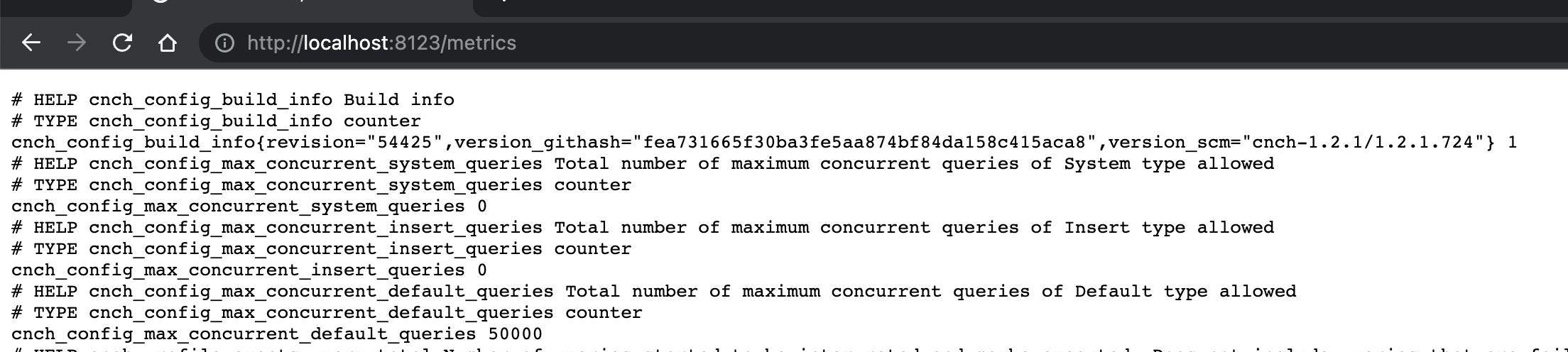
The engine spits out monitoring items under the path of the HTTP interface /metrics, the default port is 8123, and you can directly access the output of the corresponding port.
The corresponding metric output can be viewed through kubectl
kubectl port-forward -n cnch cnch-default-server-0 8123:8123
# use port-forward function to proxy port
After that, you can open localhost:8123/metrics with a browser, and you can view the indicator display as shown in the figure below. Each line corresponds to a specific index item, which conforms to the index format agreed by Prometheus.
VictoriaMetric Metric Aggregation:
Choose VictoriaMetric for the storage of indicators, which is convenient for horizontal expansion of storage and provides richer functions.
An important feature among these is the VMRule, which aggregates raw metrics. Because some of the original Prometheus indicators spit out by each component can be directly used to build monitoring alarms, the other part is more complicated and it is not easy to directly build monitoring dashboards and alarms, so it is aggregated through VWRule. The following is the rule configuration file cnch-metrics.yaml:
# Source: victoria-rules/templates/cnch-metrics.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMRule
metadata:
name: release-name-victoria-rule-cnch-metrics
namespace: cnch-operator-default-system
labels:
app: victoria-rules
chart: victoria-rules-0.1.6
release: "release-name"
heritage: "Helm"
spec:
groups:
- name: CnchMetricsLatency
rules:
# Histogram at VW level
- record: cnch:latency:queries_vw:pct95
expr: |-
histogram_quantile(0.95,
sum by (cluster, namespace, vw, le)(
rate(cnch_histogram_metrics_query_latency_bucket[5m])
)
)
# Histogram at Cluster level
- record: cnch:latency:queries_cluster:pct95
expr: |-
histogram_quantile(0.95,
sum by (cluster, namespace, le)(
rate(cnch_histogram_metrics_query_latency_bucket[5m])
)
)
# Trends Metrics
# Trend Latency VW level
- record: cnch:latency:queries_vw:pct95:avg_1d
expr: avg_over_time(cnch:latency:queries_vw:pct95[1d])
# Trend Latency Cluster level
- record: cnch:latency:queries_cluster:pct95:avg_1d
expr: avg_over_time(cnch:latency:queries_cluster:pct95[1d])
# Histogram at VW level
- record: cnch:latency:queries_vw:pct99
expr: |-
histogram_quantile(0.99,
sum by (cluster, namespace, vw, le)(
rate(cnch_histogram_metrics_query_latency_bucket[5m])
)
)
# Histogram at Cluster level
- record: cnch:latency:queries_cluster:pct99
expr: |-
histogram_quantile(0.99,
sum by (cluster, namespace, le)(
rate(cnch_histogram_metrics_query_latency_bucket[5m])
)
)
# Trends Metrics
# Trend Latency VW level
- record: cnch:latency:queries_vw:pct99:avg_1d
expr: avg_over_time(cnch:latency:queries_vw:pct99[1d])
# Trend Latency Cluster level
- record: cnch:latency:queries_cluster:pct99:avg_1d
expr: avg_over_time(cnch:latency:queries_cluster:pct99[1d])
# Trend Slow Q VW level
- record: cnch:latency:queries_vw:slow_ratio:avg_1d
expr: avg_over_time(cnch:latency:queries_vw:slow_ratio[1d])
# Trend Slow Q Cluster level
- record: cnch:latency:queries_cluster:slow_ratio:avg_1d
expr: avg_over_time(cnch:latency:queries_cluster:slow_ratio[1d])
# Slow Q VW level (Percentage of query > 10s)
- record: cnch:latency:queries_vw:slow_ratio
expr: |-
sum by (cluster, namespace, vw)(
rate(cnch_histogram_metrics_query_latency_count[5m])
- on (namespace, pod, cluster, vw, instance) rate(cnch_histogram_metrics_query_latency_bucket{le="10000"}[5m])
)
/
sum by (cluster, namespace, vw)(
rate(cnch_histogram_metrics_query_latency_count[5m])
)
# Slow Q Cluster level (Percentage of query > 10s)
- record: cnch:latency:queries_cluster:slow_ratio
expr: |-
sum by (cluster, namespace)(
rate(cnch_histogram_metrics_query_latency_count[5m])
- on (namespace, pod, cluster, vw, instance) rate(cnch_histogram_metrics_query_latency_bucket{le="10000"}[5m])
)
/
sum by (cluster, namespace)(
rate(cnch_histogram_metrics_query_latency_count[5m])
)
# Slow Q Cluster level (count queries > 10s) used by OP portal
- record: cnch:latency:queries_cluster:slow_count
expr: |-
sum by (cluster, namespace)(
increase(cnch_histogram_metrics_query_latency_count[1h])
- on (namespace, pod, cluster, vw, instance) increase(cnch_histogram_metrics_query_latency_bucket{le="10000"}[1h])
)
# Todo check if this metric became server only
- record: cnch:latency:queries_timeout:rate5m
expr: |-
sum by (cluster, namespace, pod, workload) (
rate(cnch_profile_events_timed_out_query_total[5m])
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
)
- name: CnchMetricsQPS
rules:
# Trend WG workload level
# - record: cnch:profile_events:query:total_rate5m:avg_1d
# expr: avg_over_time(sum by (cluster, namespace, workload, type) (cnch:profile_events:query:total_rate5m)[1d])
# Trend VW QPS VW level. server POV only
- record: cnch:profile_events:labelled_query_vw:total_rate5m:avg_1d
expr: avg_over_time(sum by (cluster, namespace, vw, query_type) (cnch:profile_events:labelled_query_vw:total_rate5m)[1d])
# VW QPS cluster level Todo use sum(avg_1d{vw != ""}) if no similar reenable this Trend
- record: cnch:profile_events:labelled_query_cluster:total_rate5m:avg_1d
expr: |-
avg_over_time(sum by (cluster, namespace, query_type) (cnch:profile_events:labelled_query_vw:total_rate5m)[1d])
# Trend VW Error Ratio VW level (can't sum burnrate % so we pre-recorded a burnrate summed at vw level)
- record: cnch:profile_events:labelled_query_vw_sum:error_burnrate5m:avg_1d
expr: |-
avg_over_time(cnch:profile_events:labelled_query_vw_sum:error_burnrate5m[1d])
# Number of workers in a WG that use more than 80% memory
- record: cnch:workers:high_mem_rss:80pct_count
expr: |-
(
count(
(sum(
container_memory_rss{container!="", image!=""}
* on(namespace,pod)
group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{workload=~"cnch.*worker.*|vw.*"}
) by (pod, namespace, workload)
/ sum(
kube_pod_container_resource_limits{resource="memory"}
* on(namespace,pod)
group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{workload=~"cnch.*worker.*|vw.*"}
) by (pod, namespace, workload)) > 0.80
) by (namespace, workload)
/
count(namespace_workload_pod:kube_pod_owner:relabel{workload=~"cnch.*worker.*|vw.*"}) by (namespace, workload)
)
# Byteyard Usage Profiler metrics
- record: cnch:vw:metrics:running_queries:time_milliseconds_total
expr: sum by (vw_id, cluster) (increase(cnch_internal_metrics_running_queries_time_milliseconds_total[30s]))
- record: cnch:vw:metrics:queued_queries:time_milliseconds_total
expr: sum by (vw_id, cluster) (increase(cnch_internal_metrics_queued_queries_time_milliseconds_total[30s]))
# Query Error Ratio over multiple intervals aka burn rate
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate5m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[5m])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate5m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[5m])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate5m
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate5m
- record: cnch:tso:requests:total_rate5m
expr: |-
sum(rate(cnch_profile_events_tso_request_total[5m])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate5m
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[5m])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate5m)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate5m
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[5m])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate5m)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate5m
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate5m) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate5m) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate5m
expr: |
sum(cnch:tso:requests:error_rate5m) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate5m) by (workload, cluster, namespace)
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate30m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[30m])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate30m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[30m])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate30m
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate30m
- record: cnch:tso:requests:total_rate30m
expr: |-
sum(rate(cnch_profile_events_tso_request_total[30m])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate30m
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[30m])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate30m)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate30m
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[30m])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate30m)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate30m
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate30m) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate30m) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate30m
expr: |
sum(cnch:tso:requests:error_rate30m) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate30m) by (workload, cluster, namespace)
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate1h
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[1h])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate1h
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[1h])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate1h
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate1h
- record: cnch:tso:requests:total_rate1h
expr: |-
sum(rate(cnch_profile_events_tso_request_total[1h])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate1h
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[1h])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate1h)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate1h
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[1h])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate1h)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate1h
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate1h) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate1h) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate1h
expr: |
sum(cnch:tso:requests:error_rate1h) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate1h) by (workload, cluster, namespace)
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate6h
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[6h])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate6h
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[6h])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate6h
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate6h
- record: cnch:tso:requests:total_rate6h
expr: |-
sum(rate(cnch_profile_events_tso_request_total[6h])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate6h
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[6h])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate6h)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate6h
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[6h])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate6h)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate6h
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate6h) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate6h) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate6h
expr: |
sum(cnch:tso:requests:error_rate6h) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate6h) by (workload, cluster, namespace)
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate3d
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[3d])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate3d
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[3d])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate3d
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate3d
- record: cnch:tso:requests:total_rate3d
expr: |-
sum(rate(cnch_profile_events_tso_request_total[3d])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate3d
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[3d])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate3d)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate3d
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[3d])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate3d)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate3d
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate3d) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate3d) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate3d
expr: |
sum(cnch:tso:requests:error_rate3d) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate3d) by (workload, cluster, namespace)
# Use VW level precision only 5m timeframe used for dashboard only (trend avg_1d)
- record: cnch:profile_events:labelled_query_vw_sum:error_burnrate5m
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate5m) by (cluster, namespace, vw)
/
sum(cnch:profile_events:labelled_query_vw:total_rate5m) by (cluster, namespace, vw)
# Only used for few dashboard and 1 error alert rule, no need burn rate worker+ server POV
- record: cnch:profile_events:labelled_query_unlimited:total_rate5m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="unlimited"}[5m])) by (pod, cluster, namespace, query_type)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
- record: cnch:profile_events:labelled_query_unlimited:error_rate5m
expr: |-
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="unlimited"}[5m])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
- name: CnchMetricsAvailability
rules:
- record: cnch:wg:availability
labels:
slo: error_rate
# 1 = available, 0 = unavailable
# min() check if any of the burn rate is firing (1, 1, 0) -> 0
# For any burn rate, both time window must be triggered (Multiwindow) so we use max() (1, 0) -> 1 avail
# TODO maybe change this with a ALERTS{alertstate="firing",severity="critical", alertname=~".*BudgetBurn"}
# As we can't have the 'for 15m' here see: https://github.com/metalmatze/slo-libsonnet/issues/52
expr: |
min by (cluster, namespace, vw, wg) (
max by (cluster, namespace, vw, wg) (
cnch:profile_events:labelled_query_vw:error_burnrate5m{vw=~".*"} <= bool (14.40 * (1 - 0.99)),
cnch:profile_events:labelled_query_vw:error_burnrate1h{vw=~".*"} <= bool (14.40 * (1 - 0.99))
),
max by (cluster, namespace, vw, wg) (
cnch:profile_events:labelled_query_vw:error_burnrate30m{vw=~".*"} <= bool (6.00 * (1 - 0.99)),
cnch:profile_events:labelled_query_vw:error_burnrate6h{vw=~".*"} <= bool (6.00 * (1 - 0.99))
),
max by (cluster, namespace, vw, wg) (
cnch:profile_events:labelled_query_vw:error_burnrate6h{vw=~".*"} <= bool (1.00 * (1 - 0.99)),
cnch:profile_events:labelled_query_vw:error_burnrate3d{vw=~".*"} <= bool (1.00 * (1 - 0.99))
)
)
- record: cnch:cluster:availability
expr: |
1 - (sum by (cluster, namespace) (cnch:profile_events:labelled_query_vw:error_rate5m)
/
sum by (cluster, namespace) (cnch:profile_events:labelled_query_vw:total_rate5m))
Use kubectl to execute the configuration to take effect:
kubctl apply -f cnch-metrics.yaml # Configure the corresponding rule
Monitoring service node (Server)
Important indicators
The more important indicators are excerpted below for explanation
| Metric name (the ones in double quotes are VM-aggregated)) | Description |
|---|---|
| cnch:latency:queries_cluster:pct95 cnch:latency:queries_cluster:pct99 | Query latency pct99 and pct55 |
| cnch:latency:queries_cluster:slow_ratio | The proportion of slow queries longer than 10s |
| cnch:profile_events:labelled_query_vw:total_rate5m | Total QPS of all VW |
| cnch:profile_events:labelled_query_vw:error_rate5m | Failed QPS for all VWs |
| cnch_current_metrics_query | The value of the label name query_type is insert, which is the written query |
Configure Grafana Kanban for the service node (Server)
Kanban content see screenshot
Important indicators:
| Kanban Name | Expression | Description |
|---|---|---|
| Queries Ducations | cnch:latency:queries_cluster:pct95{namespace="$namespace", cluster="$cluster"}和cnch:latency:queries_cluster:pct99{namespace="$namespace", cluster="$cluster"} | Query latency P99 和 P95 |
| Slow Queries > 10s | cnch:latency:queries_cluster:slow_ratio{namespace="$namespace", cluster="$cluster"} | The proportion of slow queries longer than 10s |
| Queries Per Second | sum(cnch:profile_events:labelled_query_vw:total_rate5m{namespace="$namespace", cluster="$cluster", workload=~"$workload"}) | Total QPS for all VWs |
| VW Queries Success | 1 - (sum by (pod) (cnch:profile_events:labelled_query_vw:error_rate5m{cluster="$cluster", namespace="$namespace", workload=~"$workload", pod=~"$pod"}) sum by (pod) (cnch:profile_events:labelled_query_vw:total_rate5m{cluster="$cluster", namespace="$namespace", workload=~"$workload", pod=~"$pod"})) | After subtracting and dividing error_rate5m and total_rate5m, the success rate is obtained |
The complete Grafana configuration file of the Server is as follows, which can be imported in the Grafana UI:cnch-server.json
Monitor TSO
important indicators
The following excerpts are some important indicators for TSO to illustrate:
| Indicators | Description |
|---|---|
| cnch:tso:requests:error_rate5m | Failed QPS for TSO components |
| cnch:tso:requests:total_rate5m | Total QPS for TSO components |
Configure Grafana Kanban for TSO
The screenshot of the board is as follows:
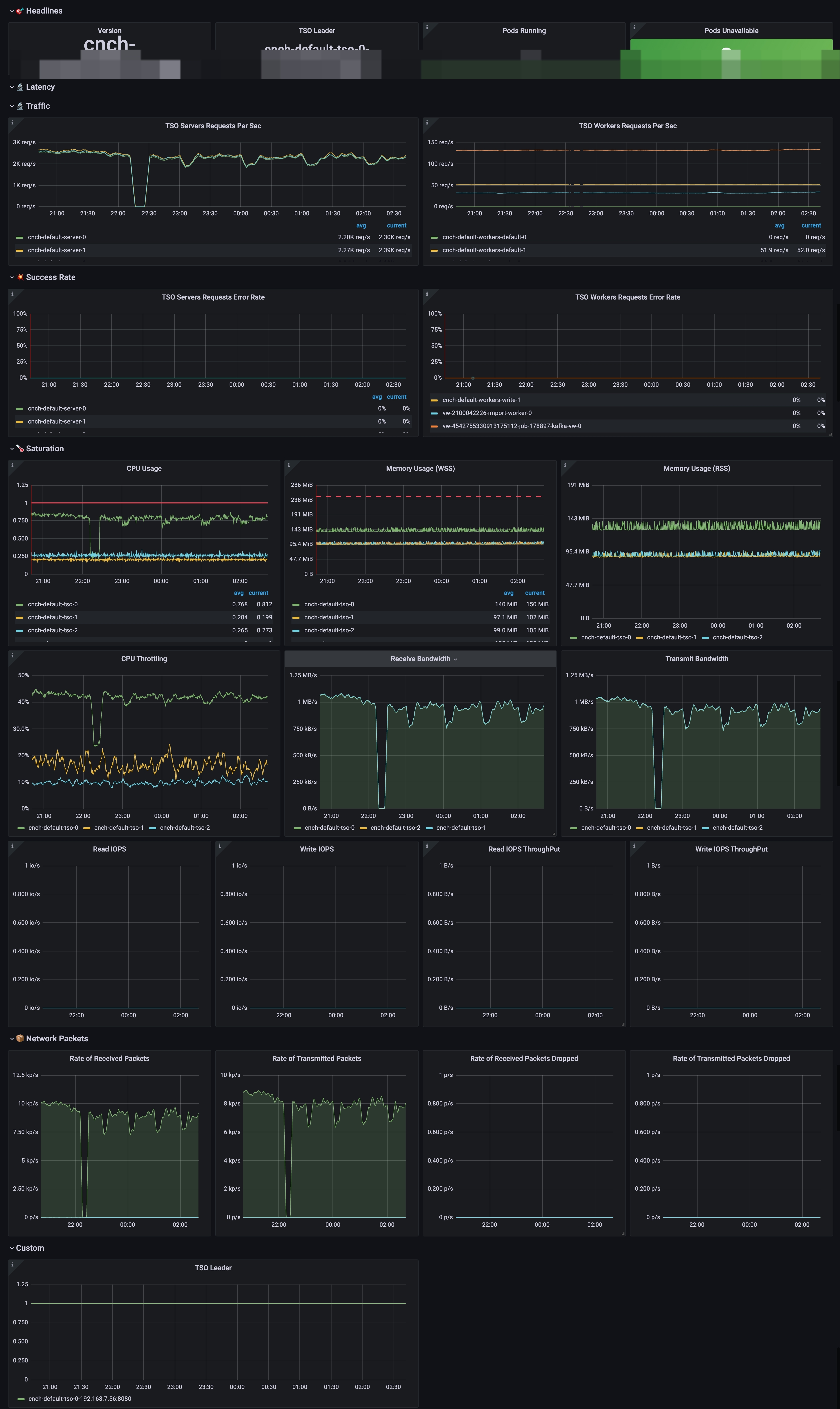
Important indicators:
| Kanban Name | Expression | Description |
|---|---|---|
| TSO Server Requests Per Sec | cnch:tso:requests:total_rate5m{namespace="$namespace", cluster="$cluster", workload=~".*server.*"} | QPS of Server component for TSO query |
| TSO Worker Requests Per Sec | cnch:tso:requests:total_rate5m{namespace="$namespace", cluster="$cluster", workload!~".*(server\|**kafka**).*"} | Remove the server and kafka, and only look at the request QPS of each worker for TSO |
| TSO Servers Requests Server Rate | cnch:tso:requests:error_rate5m{namespace="$namespace", cluster="$cluster", workload=~".*server.*"} cnch:tso:requests:total_rate5m{namespace="$namespace", cluster="$cluster", workload=~".*server.*"} | Divide error_rate and total_rate to filter the failure rate of TSO query |
The complete configuration file of TSO is as follows:cnch-tso.json
Other information that can be monitored
Other commonly used monitoring board configurations are listed here, no more screenshots
Cluster Overview: Overview of the entire cluster cnch-cluster.json
VW: detials of each Virtual Warehouse cnch-vw.json
DaemonManager: Components that manages background tasks such as Merge cnch-daemonmanager.json