监控集群
常见的监控指标
Prometheus 监控指标:
引擎在 HTTP 接口 /metrics 路径下吐出监控项,默认端口 8123,可以直接访问对应端口输出。
可通过 kubectl 查看对应的 metric 输出
kubectl port-forward -n cnch cnch-default-server-0 8123:8123
# 用port-forward功能代理端口
之后可以用浏览器打开 localhost:8123/metrics ,可查看到如下图所示的指标显示。每一行对应一个具体指标项,符合 Prometheus 约定的指标格式。
VictoriaMetric 指标聚合:
对指标的存储选择 VictoriaMetric,方便进行存储的横向扩展和提供更丰富的功能。
其中重要的功能是 VMRule,可对原始指标进行聚合。因各组件吐出的原始 Prometheus 指标其中一部分可以直接使用来构建监控告警,另一部分比较复杂,不容易直接构建监控看板和告警,所以通过 VWRule 进行聚合。以下为规则配置文件 cnch-metrics.yaml:
# Source: victoria-rules/templates/cnch-metrics.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMRule
metadata:
name: release-name-victoria-rule-cnch-metrics
namespace: cnch-operator-default-system
labels:
app: victoria-rules
chart: victoria-rules-0.1.6
release: "release-name"
heritage: "Helm"
spec:
groups:
- name: CnchMetricsLatency
rules:
# Histogram at VW level
- record: cnch:latency:queries_vw:pct95
expr: |-
histogram_quantile(0.95,
sum by (cluster, namespace, vw, le)(
rate(cnch_histogram_metrics_query_latency_bucket[5m])
)
)
# Histogram at Cluster level
- record: cnch:latency:queries_cluster:pct95
expr: |-
histogram_quantile(0.95,
sum by (cluster, namespace, le)(
rate(cnch_histogram_metrics_query_latency_bucket[5m])
)
)
# Trends Metrics
# Trend Latency VW level
- record: cnch:latency:queries_vw:pct95:avg_1d
expr: avg_over_time(cnch:latency:queries_vw:pct95[1d])
# Trend Latency Cluster level
- record: cnch:latency:queries_cluster:pct95:avg_1d
expr: avg_over_time(cnch:latency:queries_cluster:pct95[1d])
# Histogram at VW level
- record: cnch:latency:queries_vw:pct99
expr: |-
histogram_quantile(0.99,
sum by (cluster, namespace, vw, le)(
rate(cnch_histogram_metrics_query_latency_bucket[5m])
)
)
# Histogram at Cluster level
- record: cnch:latency:queries_cluster:pct99
expr: |-
histogram_quantile(0.99,
sum by (cluster, namespace, le)(
rate(cnch_histogram_metrics_query_latency_bucket[5m])
)
)
# Trends Metrics
# Trend Latency VW level
- record: cnch:latency:queries_vw:pct99:avg_1d
expr: avg_over_time(cnch:latency:queries_vw:pct99[1d])
# Trend Latency Cluster level
- record: cnch:latency:queries_cluster:pct99:avg_1d
expr: avg_over_time(cnch:latency:queries_cluster:pct99[1d])
# Trend Slow Q VW level
- record: cnch:latency:queries_vw:slow_ratio:avg_1d
expr: avg_over_time(cnch:latency:queries_vw:slow_ratio[1d])
# Trend Slow Q Cluster level
- record: cnch:latency:queries_cluster:slow_ratio:avg_1d
expr: avg_over_time(cnch:latency:queries_cluster:slow_ratio[1d])
# Slow Q VW level (Percentage of query > 10s)
- record: cnch:latency:queries_vw:slow_ratio
expr: |-
sum by (cluster, namespace, vw)(
rate(cnch_histogram_metrics_query_latency_count[5m])
- on (namespace, pod, cluster, vw, instance) rate(cnch_histogram_metrics_query_latency_bucket{le="10000"}[5m])
)
/
sum by (cluster, namespace, vw)(
rate(cnch_histogram_metrics_query_latency_count[5m])
)
# Slow Q Cluster level (Percentage of query > 10s)
- record: cnch:latency:queries_cluster:slow_ratio
expr: |-
sum by (cluster, namespace)(
rate(cnch_histogram_metrics_query_latency_count[5m])
- on (namespace, pod, cluster, vw, instance) rate(cnch_histogram_metrics_query_latency_bucket{le="10000"}[5m])
)
/
sum by (cluster, namespace)(
rate(cnch_histogram_metrics_query_latency_count[5m])
)
# Slow Q Cluster level (count queries > 10s) used by OP portal
- record: cnch:latency:queries_cluster:slow_count
expr: |-
sum by (cluster, namespace)(
increase(cnch_histogram_metrics_query_latency_count[1h])
- on (namespace, pod, cluster, vw, instance) increase(cnch_histogram_metrics_query_latency_bucket{le="10000"}[1h])
)
# Todo check if this metric became server only
- record: cnch:latency:queries_timeout:rate5m
expr: |-
sum by (cluster, namespace, pod, workload) (
rate(cnch_profile_events_timed_out_query_total[5m])
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
)
- name: CnchMetricsQPS
rules:
# Trend WG workload level
# - record: cnch:profile_events:query:total_rate5m:avg_1d
# expr: avg_over_time(sum by (cluster, namespace, workload, type) (cnch:profile_events:query:total_rate5m)[1d])
# Trend VW QPS VW level. server POV only
- record: cnch:profile_events:labelled_query_vw:total_rate5m:avg_1d
expr: avg_over_time(sum by (cluster, namespace, vw, query_type) (cnch:profile_events:labelled_query_vw:total_rate5m)[1d])
# VW QPS cluster level Todo use sum(avg_1d{vw != ""}) if no similar reenable this Trend
- record: cnch:profile_events:labelled_query_cluster:total_rate5m:avg_1d
expr: |-
avg_over_time(sum by (cluster, namespace, query_type) (cnch:profile_events:labelled_query_vw:total_rate5m)[1d])
# Trend VW Error Ratio VW level (can't sum burnrate % so we pre-recorded a burnrate summed at vw level)
- record: cnch:profile_events:labelled_query_vw_sum:error_burnrate5m:avg_1d
expr: |-
avg_over_time(cnch:profile_events:labelled_query_vw_sum:error_burnrate5m[1d])
# Number of workers in a WG that use more than 80% memory
- record: cnch:workers:high_mem_rss:80pct_count
expr: |-
(
count(
(sum(
container_memory_rss{container!="", image!=""}
* on(namespace,pod)
group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{workload=~"cnch.*worker.*|vw.*"}
) by (pod, namespace, workload)
/ sum(
kube_pod_container_resource_limits{resource="memory"}
* on(namespace,pod)
group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{workload=~"cnch.*worker.*|vw.*"}
) by (pod, namespace, workload)) > 0.80
) by (namespace, workload)
/
count(namespace_workload_pod:kube_pod_owner:relabel{workload=~"cnch.*worker.*|vw.*"}) by (namespace, workload)
)
# Byteyard Usage Profiler metrics
- record: cnch:vw:metrics:running_queries:time_milliseconds_total
expr: sum by (vw_id, cluster) (increase(cnch_internal_metrics_running_queries_time_milliseconds_total[30s]))
- record: cnch:vw:metrics:queued_queries:time_milliseconds_total
expr: sum by (vw_id, cluster) (increase(cnch_internal_metrics_queued_queries_time_milliseconds_total[30s]))
# Query Error Ratio over multiple intervals aka burn rate
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate5m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[5m])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate5m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[5m])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate5m
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate5m
- record: cnch:tso:requests:total_rate5m
expr: |-
sum(rate(cnch_profile_events_tso_request_total[5m])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate5m
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[5m])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate5m)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate5m
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[5m])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate5m)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate5m
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate5m) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate5m) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate5m
expr: |
sum(cnch:tso:requests:error_rate5m) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate5m) by (workload, cluster, namespace)
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate30m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[30m])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate30m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[30m])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate30m
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate30m
- record: cnch:tso:requests:total_rate30m
expr: |-
sum(rate(cnch_profile_events_tso_request_total[30m])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate30m
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[30m])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate30m)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate30m
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[30m])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate30m)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate30m
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate30m) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate30m) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate30m
expr: |
sum(cnch:tso:requests:error_rate30m) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate30m) by (workload, cluster, namespace)
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate1h
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[1h])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate1h
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[1h])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate1h
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate1h
- record: cnch:tso:requests:total_rate1h
expr: |-
sum(rate(cnch_profile_events_tso_request_total[1h])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate1h
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[1h])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate1h)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate1h
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[1h])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate1h)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate1h
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate1h) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate1h) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate1h
expr: |
sum(cnch:tso:requests:error_rate1h) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate1h) by (workload, cluster, namespace)
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate6h
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[6h])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate6h
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[6h])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate6h
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate6h
- record: cnch:tso:requests:total_rate6h
expr: |-
sum(rate(cnch_profile_events_tso_request_total[6h])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate6h
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[6h])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate6h)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate6h
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[6h])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate6h)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate6h
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate6h) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate6h) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate6h
expr: |
sum(cnch:tso:requests:error_rate6h) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate6h) by (workload, cluster, namespace)
# Record server POV, for vw only, the unlimited are only used for few dashboard and 1 alert rule
# Worker POV is used in workers dashboard only
- record: cnch:profile_events:labelled_query_vw:total_rate3d
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[3d])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
# Record workers POV, used by Byteyard autosuspend (server pov might not have direct insert) and workers graph
- record: cnch:profile_events:labelled_query_vw_workers:total_rate3d
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="vw"}[3d])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload!~".*server.*"}
# TEMP until byteyard support cnch:profile_events:labelled_query_vw_workers
# TODO remove this
- record: cnch:profile_event:queries_vw_only:total_rate3d
expr: |-
cnch:profile_events:labelled_query_vw_workers:total_rate3d
- record: cnch:tso:requests:total_rate3d
expr: |-
sum(rate(cnch_profile_events_tso_request_total[3d])) by (pod, cluster, namespace)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Err/s default to 0 if a request total exist (e.g. only success request) so it's included in availability
- record: cnch:profile_events:labelled_query_vw:error_rate3d
expr: |
((
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="vw"}[3d])) by (pod, cluster, namespace, query_type, vw, wg)
)
or
(
0 * group by (pod, cluster, namespace, resource_type, query_type, vw, wg) (cnch:profile_events:labelled_query_vw:total_rate3d)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel{workload=~".*server.*"}
- record: cnch:tso:requests:error_rate3d
expr: |
((
sum(rate(cnch_profile_events_tso_error_total[3d])) by (pod, cluster, namespace)
)
or
(
0 * group by (pod, cluster, namespace) (cnch:tso:requests:total_rate3d)
))
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
# Use WG level precision
- record: cnch:profile_events:labelled_query_vw:error_burnrate3d
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate3d) by (workload, cluster, namespace, vw, wg)
/
sum(cnch:profile_events:labelled_query_vw:total_rate3d) by (workload, cluster, namespace, vw, wg)
- record: cnch:tso:requests:error_burnrate3d
expr: |
sum(cnch:tso:requests:error_rate3d) by (workload, cluster, namespace)
/
sum(cnch:tso:requests:total_rate3d) by (workload, cluster, namespace)
# Use VW level precision only 5m timeframe used for dashboard only (trend avg_1d)
- record: cnch:profile_events:labelled_query_vw_sum:error_burnrate5m
expr: |
sum(cnch:profile_events:labelled_query_vw:error_rate5m) by (cluster, namespace, vw)
/
sum(cnch:profile_events:labelled_query_vw:total_rate5m) by (cluster, namespace, vw)
# Only used for few dashboard and 1 error alert rule, no need burn rate worker+ server POV
- record: cnch:profile_events:labelled_query_unlimited:total_rate5m
expr: |-
sum(rate(cnch_profile_events_labelled_query_total{resource_type="unlimited"}[5m])) by (pod, cluster, namespace, query_type)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
- record: cnch:profile_events:labelled_query_unlimited:error_rate5m
expr: |-
sum(rate(cnch_profile_events_queries_failed_total{failure_type!="QueriesFailedFromUser", resource_type="unlimited"}[5m])) by (pod, cluster, namespace, query_type, vw, wg)
* on (pod, namespace) group_left(workload) namespace_workload_pod:kube_pod_owner:relabel
- name: CnchMetricsAvailability
rules:
- record: cnch:wg:availability
labels:
slo: error_rate
# 1 = available, 0 = unavailable
# min() check if any of the burn rate is firing (1, 1, 0) -> 0
# For any burn rate, both time window must be triggered (Multiwindow) so we use max() (1, 0) -> 1 avail
# TODO maybe change this with a ALERTS{alertstate="firing",severity="critical", alertname=~".*BudgetBurn"}
# As we can't have the 'for 15m' here see: https://github.com/metalmatze/slo-libsonnet/issues/52
expr: |
min by (cluster, namespace, vw, wg) (
max by (cluster, namespace, vw, wg) (
cnch:profile_events:labelled_query_vw:error_burnrate5m{vw=~".*"} <= bool (14.40 * (1 - 0.99)),
cnch:profile_events:labelled_query_vw:error_burnrate1h{vw=~".*"} <= bool (14.40 * (1 - 0.99))
),
max by (cluster, namespace, vw, wg) (
cnch:profile_events:labelled_query_vw:error_burnrate30m{vw=~".*"} <= bool (6.00 * (1 - 0.99)),
cnch:profile_events:labelled_query_vw:error_burnrate6h{vw=~".*"} <= bool (6.00 * (1 - 0.99))
),
max by (cluster, namespace, vw, wg) (
cnch:profile_events:labelled_query_vw:error_burnrate6h{vw=~".*"} <= bool (1.00 * (1 - 0.99)),
cnch:profile_events:labelled_query_vw:error_burnrate3d{vw=~".*"} <= bool (1.00 * (1 - 0.99))
)
)
- record: cnch:cluster:availability
expr: |
1 - (sum by (cluster, namespace) (cnch:profile_events:labelled_query_vw:error_rate5m)
/
sum by (cluster, namespace) (cnch:profile_events:labelled_query_vw:total_rate5m))
可 kubectl 执行配置生效:
kubctl apply -f cnch-metrics.yaml # 配置对应rule
监控服务节点(Server)
重要指标
下面摘录比较重要的指标,进行说明
| 指标名(其中带双引号的是经过 VM 聚合的) | 说明 |
|---|---|
| cnch:latency:queries_cluster:pct95 cnch:latency:queries_cluster:pct99 | 查询延迟 pct99 和 pct55 |
| cnch:latency:queries_cluster:slow_ratio | 大于 10s 的慢查询占比 |
| cnch:profile_events:labelled_query_vw:total_rate5m | 所有 VW 的总 QPS。 |
| cnch:profile_events:labelled_query_vw:error_rate5m | 所有 VW 失败的 QPS。 |
| cnch_current_metrics_query | 其中的 label 名 query_type 值为 insert 是写入的 query |
给服务节点(Server) 配置 Grafana 看板
看板的内容看截图
摘录其中比较重要的看板进行说明:
| 看板名 | 表达式 | 说明 |
|---|---|---|
| Queries Ducations | cnch:latency:queries_cluster:pct95{namespace="$namespace", cluster="$cluster"}和cnch:latency:queries_cluster:pct99{namespace="$namespace", cluster="$cluster"} | 查询延迟的 P99 和 P95 值。 |
| Slow Queries > 10s | cnch:latency:queries_cluster:slow_ratio{namespace="$namespace", cluster="$cluster"} | 大于 10s 的慢查询占比 |
| Queries Per Second | sum(cnch:profile_events:labelled_query_vw:total_rate5m{namespace="$namespace", cluster="$cluster", workload=~"$workload"}) | 所有 VW 的总 QPS。 |
| VW Queries Success | 1 - (sum by (pod) (cnch:profile_events:labelled_query_vw:error_rate5m{cluster="$cluster", namespace="$namespace", workload=~"$workload", pod=~"$pod"}) sum by (pod) (cnch:profile_events:labelled_query_vw:total_rate5m{cluster="$cluster", namespace="$namespace", workload=~"$workload", pod=~"$pod"})) | 使用 error_rate5m 和 total_rate5m 相减和除后,得到成功率 |
Server 的完整 Grafana 配置文件如下,可在 Grafana 的 UI 导入:cnch-server.json
监控 TSO
重要指标
下面摘录对 TSO 比较重要的指标,进行说明:
| 指标名 | 说明 |
|---|---|
| cnch:tso:requests:error_rate5m | TSO 组件的失败 QPS |
| cnch:tso:requests:total_rate5m | TSO 组件的总 QPS |
给 TSO 配置 Grafana 看板
看板截图如下:
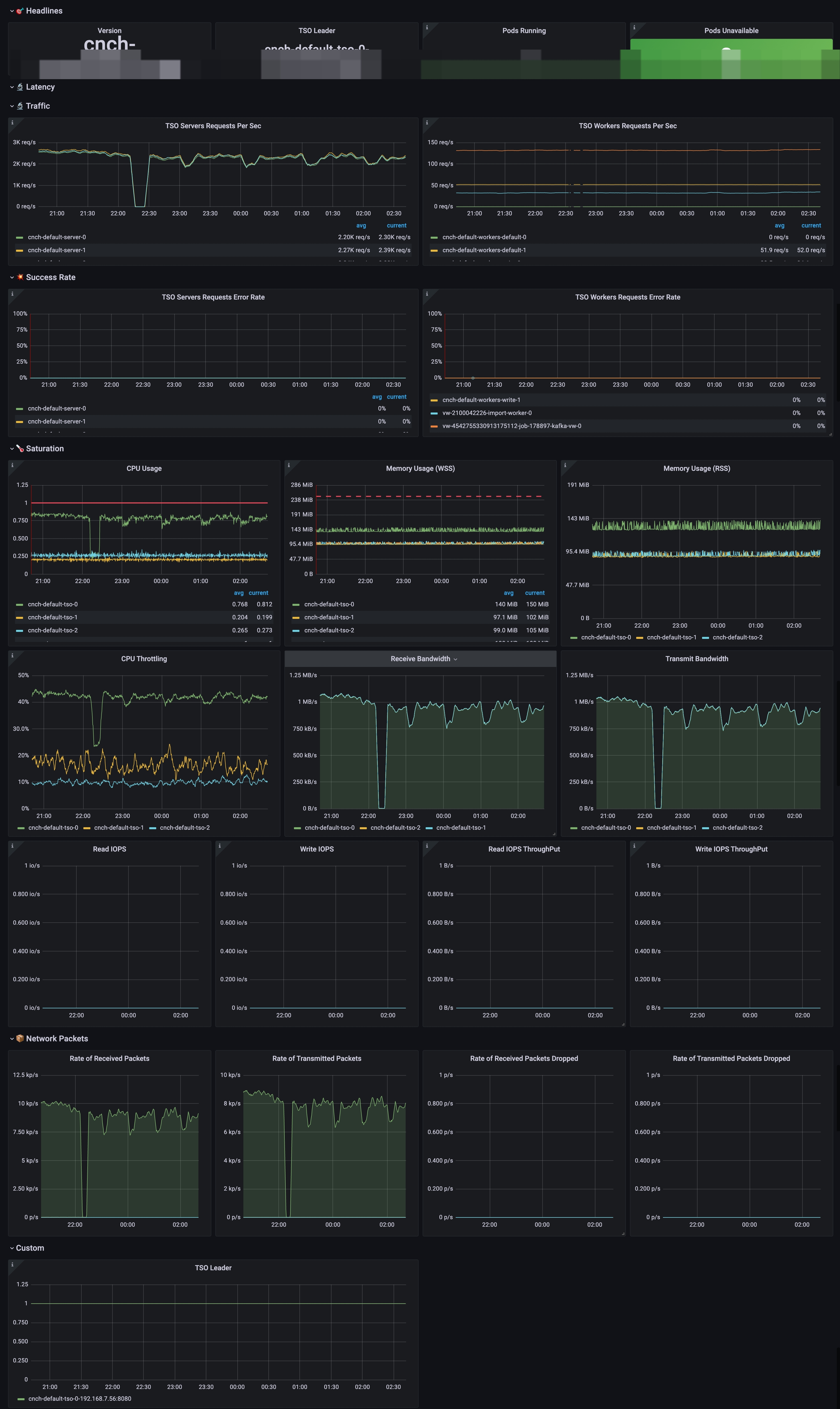
其中重要的指标说明:
| 看板名 | 表达式 | 说明 |
|---|---|---|
| TSO Server Requests Per Sec | cnch:tso:requests:total_rate5m{namespace="$namespace", cluster="$cluster", workload=~".*server.*"} | Server 组件对 TSO 查询的的 QPS |
| TSO Worker Requests Per Sec | cnch:tso:requests:total_rate5m{namespace="$namespace", cluster="$cluster", workload!~".*(server\|**kafka**).*"} | 去除 server 和 kafka,只看各 worker 对 TSO 的请求 QPS |
| TSO Servers Requests Server Rate | cnch:tso:requests:error_rate5m{namespace="$namespace", cluster="$cluster", workload=~".*server.*"} cnch:tso:requests:total_rate5m{namespace="$namespace", cluster="$cluster", workload=~".*server.*"} | 用 error_rate 和 total_rate 相除,过滤出 TSO 查询的失败率 |
TSO 完整的配置文件如下:cnch-tso.json
其他可以监控的信息
其他常用的监控看板配置此处列出,不再一一截图
Cluster Overview: 整个集群概览 cnch-cluster.json
VW: 各计算组 Virtual Warehouse 的详情 cnch-vw.json
DaemonManager: 管理 Merge 等后台任务的组件 cnch-daemonmanager.json