导入数据
文档类型:教程型
文档结构:教程目的,前置准备,分步骤讲解原理 & 示例,相关文档推荐;
内容提要:
- 支持哪些方式导入数据,导入方式上是否有建议(比如直接写入和合并 part 文件后 attach)
- 如何连接上游支持的数据源
- 如何查看数据导入情况
- 常见的导入报错该做什么
支持的数据源
提供多种数据导入方案,可以针对不同的数据源进行选择不同的数据导入方式。
按场景划分
数据源
导入方式
本地文件
流式导入数据(本地文件及内存数据)
HDFS
通过外部存储数据导入
Kafka
通过 Kafka 导入数据
通过 spark 导入
通过 Spark 导入外部数据
Mysql、Hive
通过 ByConity 访问外部数据源
支持的数据格式
导入方式
支持的数据格式
HDFS
Parquet,ORC,csv,gzip
本地文件以及内存数据
snappy 压缩格式
json, csv, TSKV,Parquet,ORC
Kafka
csv, gzip,json
导入方式
流式导入数据(本地文件及内存数据)
方式一:
方式一使用 VALUES 格式的常规语法,适合临时插入少量的数据用来测试:
INSERT INTO [db.]table [(c1, c2, c3...)] VALUES (v11, v12, v13), (v21, v22, v23), ...
其中,c1、c2、c3 是列字段声明,可忽略。VALUES 后紧跟的是由元组组成的代写入的数据,通过下标位与列字段声明一一对应。数据支持批量声明写入,多行数据之间使用逗号分隔。
例如,考虑该表:
CREATE TABLE test.insert_select_testtable
(
`a` Int8,
`b` String,
`c` Int8,
`date` Date
)
ENGINE = CnchMergeTree()
PARTITION by toYYYYMM(date)
ORDER BY tuple()
INSERT INTO insert_select_testtable VALUES (1, 'a', 1,'2022-11-10');
在使用 VALUES 格式的语法写入数据时,支持加入表达式或者函数,例如:
INSERT INTO insert_select_testtable VALUES (1, 'a', 1, now());
方式二:
方式二是使用指定格式的语法:
INSERT INTO [db.]table [(c1, c2, c3...)] FORMAT format_name data_set
ByConity 支持多种数据格式,以常用的 CSV 格式写入为例:
INSERT INTO insert_select_testtable FORMAT CSV \
1, 'a', 1, '2022-11-10'\
2, 'b', 2, '2022-11-11'
同时,还支持从文件向表中插入数据。例如:
INSERT INTO [db.]table [(c1, c2, c3)] FORMAT format_name INFILE file_name
使用上面的语句可以从客户端的文件上读取数据并插入表中,file_name 和 type 都是 String 类型,输入文件的格式一定要在 FORMAT 语句中设置。
方式三:
方式三是使用 SELECT 子句的形式,适合需要保存某张表结果并供后续查询的情况:
INSERT INTO [db.]table [(c1, c2, c3...)] SELECT ...
写入时与SELECT的列的对应关系是使用位置来进行对应的,尽管在SELECT表达式与INSERT中的名称是不同的。如果需要,会进行对应的类型转换。
通过 SELECT 子句可将查询结果写入数据表,假设需要将 insert_select_testtable_1 的数据写入 insert_select_testtable,则可以使用下面的语句:
INSERT INTO insert_select_testtable SELECT * from insert_select_testtable_1
在通过 SELECT 子句写入数据的时候,同样也支持加入表达式或者函数,例如:
INSERT INTO insert_select_testtable SELECT 1, 'a', 1, now();
虽然 VALUES 和 SELECT 子句的形式都支持声明表达式或函数,但是表达式和函数会带来额外的性能开销,从而导致写入性能下降。所以如果追求极致的写入性能。所以如果追求极致的写入性能,就应该避免使用它们。
通过外部存储数据导入
ByConity 同样支持从本地或者 HDFS 上导入数据,例如:
INSERT INTO [db.]table [(c1, c2, c3)] FORMAT format_name INFILE 'hdfs://ip:port/file_name'
使用 kakfa 导入数据
功能定义
CnchKafka 是 ByConity 基于社区 ClickHouse Kafka 表引擎自研实现的适配云原生架构的表引擎,用于高效快速地将用户数据从 Apache Kafka 实时导入 ByConity;其设计与实现既适配了云原生新架构,同时在社区实现基础上增强了部分功能。
CnchKafka 主要功能特点包括:
- 提供基于云原生架构优势的自动容错能力,降低运维成本;
- 可扩展的消费能力:支持通过 SYSTEM 命令调节消费者数目,最高适配 topic 对应的 partition 数;
- 增强消费语义:依赖 Transaction 保证,通过引擎管理 offset 实现 Exactly-Once 消费语义;
- 消费性能:很大程度依赖用户表的 schema 复杂度,通常经验值 2k-2M 条/秒,吞吐 15MiB/s 左右;
- 支持多种数据类型,包括但不限于 Json、ProtoBuf、CSV 等;
- 支持记录消费日志,既方便排查问题,也提供了数据审计的能力。
实现原理
概述
CnchKafka 继承了社区的基本设计,即通过一个 <CnchKafka 消费表、Materialized View 物化视图表、存储表 > 三元组实现整个消费链路,其中:
- CnchKafka 消费表:负责订阅 Kafka topic 并消费消息;将得到的消息解析后写为 Block;
- Materialized View 物化视图表:构建从消费表到存储表的数据通路,将 CnchKafka 消费的 Block 写入存储表,并提供简单的过滤功能;
- 存储表:支持 Cnch 多种 MergeTree 存储表。
基本数据通路如下:
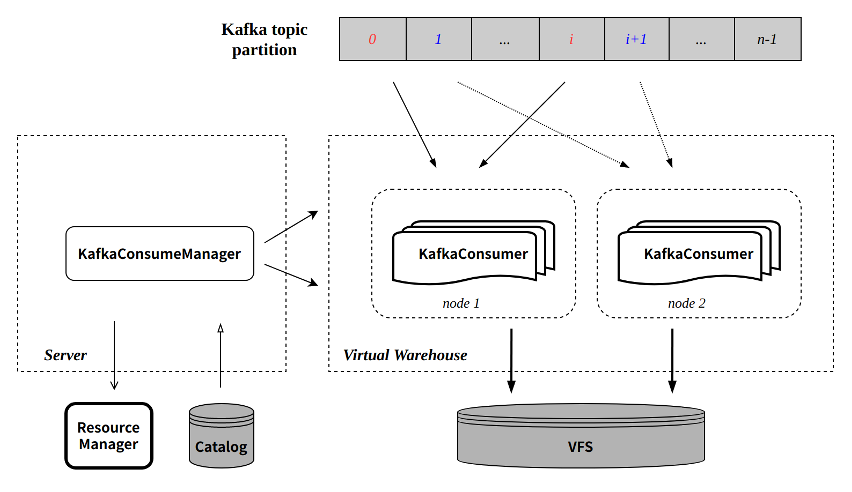
图中各组件是 ByConity 云原生架构部分涉及 CnchKafka 的组件,为避免读者不了解,此处对各组件做简单说明;但限于篇幅和重点,更详细的架构设计细节请参考架构文档。
- Server
- 应用接入层,所有查询和导入任务的入口;
- 轻量级设计,本身不做具体查询和导入,主要负责任务调度转发和元数据访问,包括:
- 预处理查询请求,从 Catalog 读取元数据,将原数据和查询 sql 下发查询节点,将查询结果返回上层(调用接口或用户等);
- 管理导入任务:选择导入节点执行导入任务;
- 和 Catalog 交互,查询或更新元数据;
- 和 Resource Manager 交互,选择任务执行节点保证负载均衡;
- Virtual WareHouse
- 计算层,所有查询和导入任务的执行节点,无状态服务;
- 支持租户独享,实现资源和数据隔离;
- 支持读写分离,查询和导入可创建和指定不同 Virtual WareHouse;
- Catalog
- KV 数据库,用于元数据管理,包括数据库表元信息、part 元信息等;
- CnchKafka 消费 offset 也存储在 catalog;
- VFS
- 底层存储,支持多种存储系统,包括 HDFS、S3 等。
KafkaConsumeManager
每张 CnchKafka 消费表会在 Server 层启动一个 Manager 负责调度和管理所有的消费者任务。Manager 本身是 Server 端的一个常驻线程,通过 Server 的高可用和 DaemonManager 保证其服务稳定。
KafkaConsumeManager 主要实现和功能包括:
- 根据配置的 consumer 数目将 topic partition 均匀分发到每个 consumer;
- 与 Catalog 交互,获取 partition 消费的 offset;
- 调度 consumer 到配置的 Virtual Warehouse 节点执行:
- 节点选择支持多种策略配置,保证负载均衡;
- 定期探活每个 consumer 任务,保证任务执行的稳定性。
KafkaConsumer
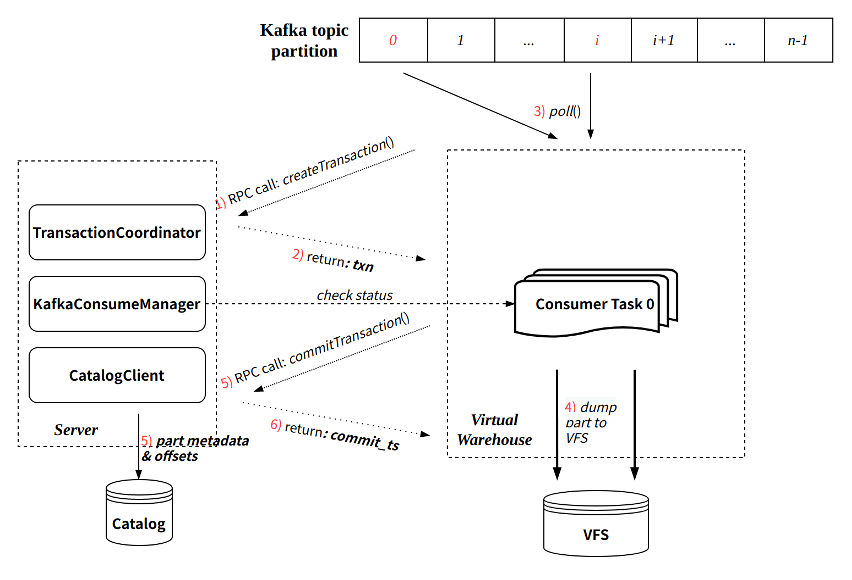
每个 KafkaConsumer 实现为一个常驻线程在 Virtual Warehouse 节点执行,负责从指定的 topic partition 消费数据,转换为 part 写入 VFS,并将元信息提交回 Server 端写入 Catalog。主要特点:
- 继承社区的攒批写入模式(每次消费周期默认 8 秒);
- 每次消费过程通过 Transaction 保证原子性:
- 通过与 Server RPC 交互创建事务;
- 事务提交会同时提交写入的 part 元信息以及最新消费的 offset。
单次消费执行流程可参考下图:
Exactly-Once
与社区实现相比,CnchKafka 实现增强了消费语义,即从社区的 At-Least-Once 语义,升级为 Exactly-Once 语义。这主要得益于新架构 Transaction 事务的保证。
由于每轮消费都会通过事务管理,且每次提交数据元信息的同时提交对应的 offset。由于事务保证了提交的原子性,那么数据元信息和 offset 要么同时提交成功,要么都提交失败。
这样就保证了数据和 offset 始终一致,每次消费重启都从上次提交的 offset 位置继续消费,从而实现了 Exactly-Once。
自动容错实现
CnchKafka 整体容错策略采取快速失败方式,即:
- KafkaConsumeManager 定期探活 consumer 任务,探活失败,立即拉起一个新的 consumer;
- KafkaConsumer 每次执行中,与 Server RPC 的两次交互(创建事务和提交事务)都会向 Manager 校验自身的有效性,如果校验失败(比如 Manager 已经拉起了一个新的 consumer 等),会主动 kill 自己。
使用指南
建表
创建 CnchKafka 消费表和社区原生建 Kafka 表类似,需要通过 Setting 参数配置 Kafka 数据源及消费参数。示例如下:
CREATE TABLE kafka_test.cnch_kafka_consume
(
`i` Int64,
`ts` DateTime
)
ENGINE = CnchKafka()
SETTINGS
kafka_broker_list = '10.10.10.10:9092', -- replace with your own broker list
kafka_topic_list = 'my_kafka_test_topic', -- topic name to subcribe
kafka_group_name = 'hansome_boy_consume_group', -- your consumer-group name
kafka_format = 'JSONEachRow', -- always be json
kafka_row_delimiter = '\n', -- always be \n
kafka_num_consumers = 1
(Setting 参数说明及其他更多参数支持请参考下方说明)
由于 Kafka 消费设计需要三张表,所以还需要同步创建另外两张表。
首先创建存储表(以 CnchMergeTree 为例):
CREATE TABLE kafka_test.cnch_store_kafka
(
`i` Int64,
`ts` DateTime
)
ENGINE = CnchMergeTree
PARTITION BY toDate(ts)
ORDER BY ts
最后创建物化视图表(必须 Kafka 表和存储表创建成功后才能创建):
CREATE MATERIALIZED VIEW kafka_test.cnch_kafka_view
TO kafka_test.cnch_store_kafka
(
`i` Int64,
`ts` DateTime
)
AS
SELECT * -- you can add virtual columns here if you need
FROM kafka_test.cnch_kafka_consume
如果你有对应 topic 的消费权限,那么三张表创建好以后,消费就会自动开始执行。
虚拟列支持
有时候业务需要获取 Kafka 消息的元数据(e.g. 消息的 partition, offset 等)。此时可以使用 virtual columns 功能来满足这个需求。virtual columns 不需要在建表的时候指定,是表引擎本身的属性。可以放到 VIEW 表的 SELECT 语句中存储到底表中(当底表添加了对应列):
SELECT
_topic, -- String
_partition, -- UInt64
_key, -- String
_offset, -- UInt64
_content, -- String: 完整的消息内容
* -- 正常列可以通过*展开,虚拟列则不能
FROM kafka_test.cnch_kafka_consume
Setting 参数说明
参数名
类型
必填/默认值
说明
kafka_cluster / kafka_broker_list
String
必填
公司内部 Kafka 集群;
社区版本 Kafka 请使用 kafka_broker_list 参数
kafka_topic_list
String
必填
可以多个,逗号分隔
kafka_group_name
String
必填
consumer group name,消费组
kafka_format
String
必填
消息格式;目前最常用 JSONEachRow
kafka_row_delimiter
String
'\0'
一般使用 '\n'
kafka_num_consumers
UInt64
1
消费者个数,建议不超过 topic 中最大 partition 数目
kafka_max_block_size
UInt64
65536
写入 block_size,上限 1M
kafka_max_poll_interval_ms
Milliseconds
7500
the max time to poll from broker each iteration
kafka_schema
String
""
schema 文件设置参数,以文件名 + 冒号 + 消息名格式设置
如: schema.proto:MyMessage
kafka_format_schema_path
String
""
远端 schema 文件路径(不含文件名)设置参数,目前只支持 hdfs.
(如果没有设置这个参数,将从配置文件设置的默认路径读取)
kafka_protobuf_enable_multiple_message
bool
true
设置为 true,表示可以从一条 kafka 消息中读取多个 protobuf 的 message,彼此以各自长度为间隔
kafka_protobuf_default_length_parser
bool
false
仅在 kafka_protobuf_enable_multiple_message 为 true 生效:true 表示消息头部有变量记录长度;false 表示用一个固定的 8 字节作为头部记录长度。
kafka_extra_librdkafka_config
Json format string
""
(More params refer to here)
其他 rdkafka 支持的参数,通常用于鉴权
- SCRAM: "{"sasl.mechanisms":"SCRAM-SHA-512","sasl.password":"*","sasl.username":"bytehouse-dev","security.protocol":"sasl_ssl","ssl.ca.location":""}"
- PLAIN: "{"sasl.mechanisms":"PLAIN","sasl.password":"admin","sasl.username":"admin","security.protocol":"sasl_plaintext"}"
cnch_vw_write
String
"vw_write"
配置消费使用 Virtual WareHouse,consumer 任务将被调度到配置的 Virtual Warehouse 节点执行
kafka_cnch_schedule_mode
String
"random"
ConsumeManager 调度 consumer 任务时候采取的调度策略,目前支持:random, hash, and least_consumers;如果是独立 vw 或消费者数目大于 10,推荐使用 least_consumers
修改消费参数
支持通过 ALTER 命令快速修改 Setting 参数,主要用于调整消费者数目等提升消费能力。
命令:
ALTER TABLE <cnch_kafka_name> MODIFY SETTING <name1> = <value1>, <name2> = <value2>
该命令执行会自动重启消费任务。
手动启停消费
在一些场景中用户可能需要手动停止消费,随后手动恢复;我们提供了对应的 SYSTEM 命令实现:
SYSTEM START/STOP/RESTART CONSUME <cnch_kafka_name>
注意:START/STOP 命令会将对应状态持久化到 Catalog,因此在执行 STOP 命令后,如果不执行 START,即使服务重启,消费任务也不会恢复。
重置 offset
由于 CnchKafka 的 offset 由引擎自身管理和保存,当用户需要重启 offset 时,我们同样实现了 SYSTEM 命令操作。具体支持以下三种方式:
A 重置到特殊位置:最新位置/起始位置
命令:
SYSTEM RESET CONSUME OFFSET '{"database_name":"XXX", "table_name": "XXX", "offset_value":-1}'
可能的特殊位置的 value 值:
enum Offset {
OFFSET_BEGINNING = -2,
OFFSET_END = -1,
OFFSET_STORED = -1000,
OFFSET_INVALID = -1001
};
B 按时间戳重置
(版本要求 >= cnch-1.4)命令:
SYSTEM RESET CONSUME OFFSET '{"database_name":"XXX", "table_name": "XXX", "timestamp":1646125258000}'
其中 timestamp 的值应该为 Kafka 侧数据有效期内的某个时间的时间戳,且为毫秒级。
C 指定 offset 具体 value
system reset consume offset '{"database_name":"XXX", "table_name": "XXX", "topic_name": "XXX", "offset_values":[{"partition":0, "offset":100}, {"partition":10, "offset":101}]}'
指定特定 topic partition 到特定 offset value,比较少见。
运维手册
常见消费性能调优
当消费持续出现 lag,通常为消费能力不足。CnchKafka 建表默认 1 个消费,单次消费写入最大 block size 为 65536. 当消费能力不足时,优先调整消费者和 block-size 参数。调整方式参考上文修改消费参数
调整 max-block-size
- 该参数直接影响消费内存使用,值越大所需内存越大。对于一些单条数据较大的消费表,谨慎调整该参数,避免爆内存。(上限为 1M)
- 当用户对数据延时要求不高,且数据量大 内存充足时,可同步调整此参数以及“kafka_max_poll_interval_ms”参数,让每一轮消费时间增加,每次写入的 part 变大,降低 MERGE 压力,提升查询性能。
调整 num_consumers
- 该参数上限为消费 topic 对应的 partition 数目。
- 在消费无 lag 情况下,尽可能减少此参数(即避免无意义增大此参数),减少资源使用,同时避免消费产生过多碎 part,增大 MERGE 压力,且不利于查询。
用于辅助排查的系统表
消费事件:cnch_system.cnch_kafka_log
kakfa_log 表记录了一些消费的基本事件,开启需要在 config.xml 中配置 kafka_log 项(server&worker 均需配置),重启之后生效。
kafka_log 在 Virtual Warehouse 由 consumer 任务写入,实时汇聚到全局的 cnch_system.cnch_kafka_log 表中,实现从 Server 段查看所有消费表的消费记录。
字段说明
列名
类型
说明
event_type
Enum8
见下表
event_date
Date
时间发生日期。分区字段,建议每次查询都带上。
event_time
DateTime
时间发生时间,单位秒
duration_ms
UInt64
事件持续时间,单位秒
cnch_database
String
CnchKafka 库名
cnch_table
String
CnchKafka 表名
database
String
consumer 任务库名(目前同 cnch_database)
table
String
consumer 任务表名(通常为 cnch_table 加时间戳及消费者编号后缀)
consumer
String
消费者编号
metric
UInt64
消费行数
has_error
UInt8
1 代表有异常;0 代表无异常。
exception
String
异常说明,
事件说明
UInt8 值
String 值
说明
1
POLL
metric 表示消费了多少条数据,duration_ms 覆盖了一次完整的消费流程,包含 WRITE 的时间。
2
PARSE_ERROR
metric 表示解析出错的消费条数,如果有多条解析出错,仅挑选一条打印出来。
3
WRITE
metric 表示写入数据的行数,duration_ms 基本上等同于数据持久化的时间
4
EXCEPTION
消费过程的异常。常见的有:鉴权异常,数据持久化失败,VIEW SELECT 执行失败。
5
EMPTY_MESSAGE
空消息条数。
6
FILTER
写入阶段被过滤的数据。
7
COMMIT
最后事务提交记录,只有该条记录才表示数据写入成功,可作为数据审计标准
消费状态:system.cnch_kafka_tables
kafka_tables 记录了 CnchKafka 表的实时状态,默认开始,为内存表;
字段说明
字段名
数据类型
说明
database
String
数据库名
name
String
Kafka 表名
uuid
String
kafka 表唯一标识 UUID
kafka_cluster
String
kafka 集群
topics
Array(String)
消费 topic 列表
consumer_group
String
所属消费组
num_consumers
UInt32
当前实际正在执行的消费者数目
consumer_tables
Array(String)
各个消费者对应的数据表名
consumer_hosts
Array(String)
各个消费者分发到的执行节点
consuemr_partitions
Array(String)
各个消费者分配到的需要消费的 partition
常见排查消费异常记录
查看 CnchKafka 消费表实时状态
SELECT * FROM system.cnch_kafka_tables
WHERE database = <database_name> AND name = <cnch_kafka_table>
查看最近消费记录
SELECT * FROM cnch_system.cnch_kafka_log
WHERE event_date = today()
AND cnch_database = <database_name>
AND cnch_table = <cnch_kafka_table>
AND event_time > now() - 600 -- 最近十分钟
ORDER BY event_time
按小时统计当天消费记录
SELECT
toHour(event_time) as hour,
sumIf(metric, event_type = 'POLL') as poll_rows,
sumIf(metric, event_type = 'PARSE_ERROR') as error_rows,
sumIf(metric, event_type = 'COMMIT') as commit_rows
FROM cnch_system.cnch_kafka_log
WHERE event_date = today()
AND cnch_database = <database_name>
AND cnch_table = <cnch_kafka_table>
GROUP BY hour
ORDER BY hour
通过 Spark 导入外部数据
使用part writer工具导入ByConity,part writer工具可以不经过ByConity引擎,直接将数据文件转化为part文件。使用part writer可以实现ByConity查询与构建分离,一定程度缓解数据导入和查询的资源竞争,提高查询性能。目前,part writer及ByConity对应的加载part文件功能的开发基本完成,下面介绍如何使用part writer将数据导入到ByConity。
(1)使用part writer生成part文件
part writer 接收一个 sql 语句作为参数,用户通过 sql 语句指定源数据文件、数据文件格式、数据 schema、part 文件保存路径等详细信息,使用方式如下:
./part_writer "load CSV file '/path/to/data/test.csv' as table db.tablename(col1 UInt64, col2 String, col3 Nullable(String)) partition by col1 order by (col2, col3) location '/path/to/dest/'"
示例 SQL 中,
- ‘CSV’指定源数据文件格式;此外,part writer 还可使用 CSVWithNames, JSONEachRow 等多种 clickhouse 原生支持的数据文件格式。
- '/path/to/data/test.csv' 指定了源数据文件;支持从本地和 hdfs 读取源数据。如使用 hdfs 数据文件,指定路径为:‘hdfs://host:port/path/to/data/file’;
- '/path/to/dest/'指定 part 文件写入的目标文件夹;支持将 part 文件直接写到 hdfs 上,ByConity 可以从 hdfs 上拉取并加载 part 文件。
- as table 指定了插入数据的 schema 信息
- partition by 和 order by 分别指定了数据表的分区键和排序键,多个键之间使用逗号进行分割并且需要用圆括号包裹, 如: partition by (name, id)。
- ByConity 特殊选项,settings cnch=1,用于将生成的 part 直接 dump 成 ByConity 的 part 格式并写入 location 选项指定的 hdfs 路径。
(2)part 文件导入 ByConity
生成好的 part 文件可以直接 copy 到 ByConity 表对应的数据文件路径下,然后通过重启 ByConity server 加载;
也可以将 part 文件目录 copy 到表的 detached 目录下,通过 attach 命令加载 part 文件, 如
alter table test attach part 'partfile'
如果使用 part writer 生成 part 文件时指定了直接上传到 hdfs,可以执行如下命令:
system fetch parts into db.table 'hdfs://host:port/path/to/part/'
ByConity 将自动从 hdfs 路径下拉取 part 文件并进行加载。
ByConity attach 语法:
用于将 dump 到 hdfs 的 parts 导入到目标表:
alter table test attach parts from '/hdfs/path/to/dumped/dir'
同时,形式四还支持 spark 导入:
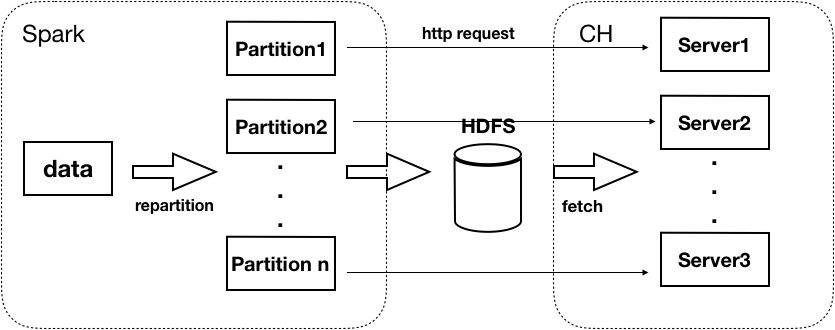
实际应用场景下,需要往 ByConity 集群导入大量数据,可以考虑使用 spark。首先从外部将数据读入 spark dataset;然后根据 sharding key 对 dataset 进行 repartition,保证将要发送到不同 ByConity 节点到数据落在不同的 partition 上(可能需要根据实际情况,调整 spark.sql.shuffle.partitions 参数使 partition 不小于 ByConity 主节点数);对于每个 partition, 首先通过调用 part writer 生成 part 文件,并指定 part 文件上传到 hdfs,然后通过向对应 ByConity 节点发送 http 请求,通知 ByConity 加载 part 文件。数据流图如下:
通过 ByConity 访问外部数据源
MySQL
MySQL 引擎允许用户通过 ByConity 访问 MySQL 表,并可以进行 SELECT 和 INSERT 查询。
在 MySQL 中创建表
- 创建 database
CREATE DATABASE db1;
- 在 mysql 中创建表
CREATE TABLE db1.table1(
id Int,
column1 VARCHAR(255)
);
- 插入一些数据
INSERT INTO db1.table1
(id, column1)
values
(1, 'mysql-ab'),
(2, 'mysql-cd');
- 在 mysql 中创建 user 以在 ByConity 中连接 mysql
CREATE USER 'mysql_byconity'@'%' IDENTIFIED BY 'Password123!';
- 授予权限。(这里为了展示,授予了
mysql_byconity用户 admin 权限)
GRANT ALL PRIVILEGES ON *.* TO 'mysql_byconity'@'%';
在 ByConity 中创建 MySQL 表
Now let's create a ByConity table that uses the MySQL table engine:
CREATE TABLE mysql_table1 (
id UInt64,
column1 String
)
ENGINE = MySQL('mysql-host.domain.com','db1','table1','mysql_byconity','Password123!');
MySQL 引擎的参数如下表:
参数
描述
例子
host
域名或 IP:Port
mysql-host.domain.com
database
mysql 数据库名
db1
tabele
mysql 表名
table1
user
连接 mysql 的用户
mysql_byconity
password
连接 mysql 的密码
Password123!
在 ByConity 中测试连接 mysql 表
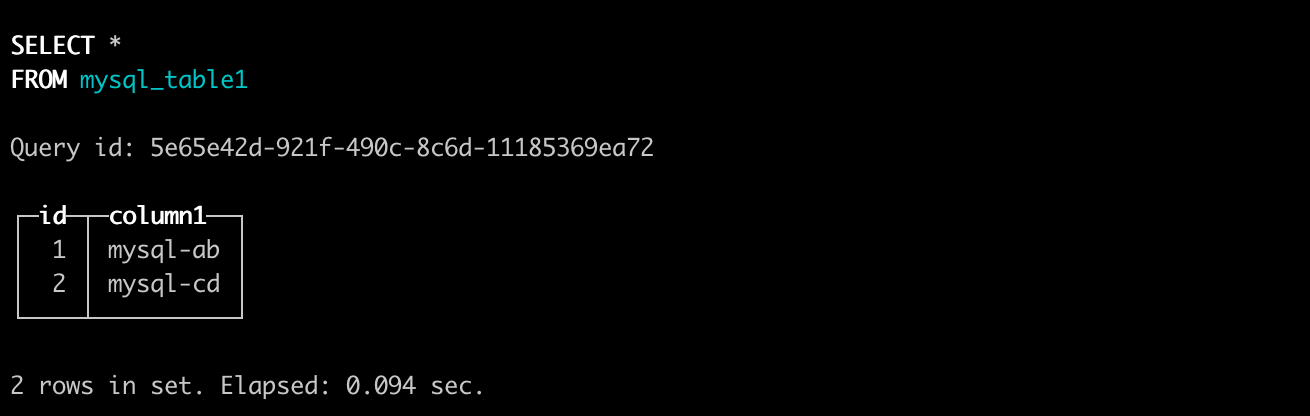
- 测试 SELECT 查询
select * from mysql_table1;
- 测试 INSERT 查询
INSERT INTO mysql_table1
(id, column1)
VALUES
(3, 'byconity-test');
- 在 MySQL 中验证从 ByConity 中插入的数据
mysql> select id, column1 from db1.table1;

Hive
CnchHive为ByConity提供的一种表引擎,支持使用外表的方式进行联邦查询,用户无需通过数据导入,可以直接进行数据查询加速。
使用:
实例 1:构建 hive 表的全集
--创建hive外表
CREATE TABLE t
(
client_ip String,
request String,
status_code INT,
object_size INT,
date String
)
ENGINE = CnchHive('psm', 'hive_database_name', 'hive_table_name')
PARTITION BY date;
--参数说明:
--psm:hivemetastore psm
--hive_database_name:hive表database name
--hive_table_name:hive表table name
--查询hive外表
select * from t where xxx;
实例 2:构建 hive 表的子集
CREATE TABLE t
(
client_ip String,
request String,
date String
)
ENGINE = CnchHive('psm', 'hive_database_name', 'hive_table_name')
PARTITION BY date
--参数说明:
--psm:hivemetastore psm
--hive_database_name:hive表database name
--hive_table_name:hive表table name
--查询hive外表
select * from t where xxx;
实例 3:hive bucket 表构建
CREATE TABLE t
(
client_ip String,
request String,
device_id String,
server_time String,
date String
)
ENGINE = CnchHive('psm', 'hive_database_name', 'hive_table_name')
PARTITION BY date
CLUSTER BY device_id INTO 65536 BUCKETS
ORDER BY server_time
SETTINGS cnch_vw_default ='vw_default'
--参数说明:
--psm:hivemetastore psm
--hive_database_name:hive表database name
--hive_table_name:hive表table name
--查询hive外表
select * from t where xxx;
说明:
- 外表列
- 列名需要与 hive 表一一对应
- 列的顺序不需要与 hive 一一对应
- 可以只选择 hive 表中的部分列,但分区列必须要全部包含。
- 外表列的分区需要通过 partition by 语句指定,同时需要与普通列一样定义到描述列表中。
- 当 Hive 表为 bucket 表时,建 CnchHive 引擎时需指定分桶列以及分桶数量。(CLUSTER BY xxx INTO xxx BUCKETS )
- 当 Hive 表中有 ORDER BY 字段,建 CnchHive 引擎时需指定 ORDER BY 字段。
- ENGINE 指定为 CnchHive
- 引擎参数
- psm:hivemetastore psm
- hive_database_name:指定 hive 中的数据库
- hive_table_name:指定 hive 中的表,不支持 view。
- 支持的列类型对应关系如下表:
hive 列类型
CnchHive 列类型
描述
INT/INTERGER
INT/INTERGER
BIGINT
BIGINT
TIMESTAMP
DateTime
STRING
String
VARCHAR
FixedString
内部转换为 FixedString
CHAR
FixedString
内部转换为 FixedString
DOUBLE
DOUBLE
FLOAT
FLOAT
DECIMAL
DECIMAL
MAP
Map
ARRAY
Array
说明:
- hive 表 schema 变更不会自动同步,需要在 Clickhouse 中重建 hive 外表
- 当前 hive 存储格式仅支持 Parquet
- 当前 CnchHive 不支持 insert、alter 操作
SETTINGS
cnch_vw_default:用于指定 vw。
max_read_row_group_threads:用于指定并发读取 Parquet row group 的并发数量。
运维手册
关键字
解决办法
DB::Exception: Can not insert NULL data into non-nullable column "name"
列字段添加 Nullable 属性。
DB::Exception: The hive type is not match in cnch.
CnchHive schema type 与 Hive schema 不匹配。
DB::Exception: column name xxx doesn't match.
CnchHive schema name 与 Hive schema 不匹配。
DB::Exception: CnchHive only support parquet format. Current format is org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat.
CnchHive 目前仅支持存储格式为 Parquet。
DB::Exception: No available nnproxy xxx.
HiveMetastore 的 psm 有问题,需 check HiveMetastore psm 是否可访问。
常见报错及处理
关键字
原因
解决办法
Too many map keys in table
(more than 10000)
Map 列中 key 种类超 10000
超 10000 则无法导入,请导入数据减少 map key 数量
Memory limit (total)
导入过程中内存超限制
Cannot parse JSON
json 中数据类型与 clickhouse 的不符
请用户检查上游生成数据类型是否匹配;
Duplicate field found while parsing JSONEachRow format: hour
json 数据有字段重复,这里的重复字段是 hour,即"format:"后的就是重复字段
检查上游数据是否正确,配置是否正确
HDFS json size xxx > 1099511627776
导入数据太大(1T),禁止导入
减少导入数据量
Unable to parse hdfs json file
hdfs 中数据格式错误
请用户检查 hdfs 中文件是否为合法的 json
DB::Exception: Error while reading parquet data: IOError: definition level exceeds maximum. Stack trace
hdsf 文件错误读取错误,多数为丢块等造成。
需要重新生产 HDFS 文件
DB::Exception: Cannot parse string 'time="2021-11-12' as Date: syntax error at position 10 (parsed just 'time="2021'). Note: there are toDateOrZero and toDateOrNull functions, which returns zero/NULL instead of throwing exception.: while pushing to view
这种情况是用户 topic 中有脏数据;Kafka 表消费的时候按 string 正常解析;但是写入底表通过 toDate 等函数转换发现不合法,导致写入失败阻塞消费
1.临时可修改 VIEW 表,过滤脏数据;
2.用户上游添加数据清洗和保护机制
3.Kafka 表解析与底表保持一致,不建议在写入阶段再转换,Kafka 解析失败可以丢弃脏数据,不阻塞整个消费
Code: 1001, type: cppkafka::Exception, e.what() = Failed to create consumer handle: consumer regist error, please check output!
打开 trace 日志,查看 Kafka 侧具体报错信息
根据报错信息处理
Code: 49, e.displayText() = DB::Exception: Check dependencies failed for
VIEW 表找不到
重建 VIEW 表
Code: 6001. DB::Exception: DB::Exception: Cannot get metadata of table XXX by UUID : XXX.
执行 ALTER TABLE 命令时报错,cnch 表是和 server 绑定,这个是由于没在表对应 server 执行导致
先查询 system.cnch_table_host 获得该表对应的 server,然后在对应 server 执行
No space left on device: while pushing to view
磁盘用满
清理磁盘
导入参数调优
直接写入方式调优
在使用 INSERT VALUES, INSERT INFILE 或者 PartWriter 工具写入时,最后生成的 Part 数量会影响写入 HDFS 的次数进而影响写入整体的耗时,因此应当尽量减少 Part 的数量。直接写入的流程如下:
- 读取部分文件数据
- 将这部分数据按照 PartitionBy 进行切分
- 将这部分数据按照 ClusterBy 进行切分
- 将切分完的数据写成新的 Part 并写入 HDFS
调优手段:
- 为了减少 Part 的数量,我们可以将文件中具有相同的分区和 Bucket 的数据排列在一起,这样每次读取一些新的数据后,生成的 Part 数量会尽可能少。可以将数据按照分区相同,分区内 Bucket 相同的要求进行排序,Bucket 的计算规则是:
- 如果没有指定 SPLIT_NUMBER,会将 ClusterByKey 所使用的列计算 SipHash 后对 BucketNumber 取模得到 BucketNumber
- 如果指定了 SPLIT_NUMBER
- 计算 SplitValue
- 如果 ClusterBy 某一列,利用 dtspartition 函数计算出对应的 SplitValue
- 如果 ClusterBy 多列,则将这些列利用 SipHash 计算出对应的 SplitValue
- 计算 BucketNumber
- 如果是 WithRange,则用 SplitValue * BucketCount / SplitNumber 计算对应 BucketNumber
- 如果不是 WithRange,则用 SplitValue % BucketCount 计算对应 BucketNumber
- 读取文件时
- 如果每行数据大小并不大,可以通过调大 max_insert_block_size 来一次读取更大的 Block,从而生成更大的 Part
- 如果读取的文件不是 HDFS/CFS 的,同时使用通配符匹配了多个文件,也可以同时调大 min_insert_block_size_rows 和 min_insert_block_size_bytes