复杂查询调优
复杂查询执行模型
分析型查询可以分为简单查询和复杂查询,简单查询通常是单表检索聚合、大表与小表 Join 查询,查询响应快;复杂查询指的是有大表、多表关联和复杂的逻辑处理,通常查询响应慢消耗资源多。ByConity 在复杂查询上进行了优化设计。 简单的查询可以采用两阶段执行模型,计算节点上面执行的 partial 阶段,服务节点上面执行的 final 阶段,一旦我们需要执行一个复杂的多个聚合或者 join 的查询,两阶段的执行模型灵活性非常低,也让查询的优化变得棘手。为了更好的支持分布式查询,方便执行优化器产生的执行计划,我们引入了支持多轮分布式执行模式的复杂查询。
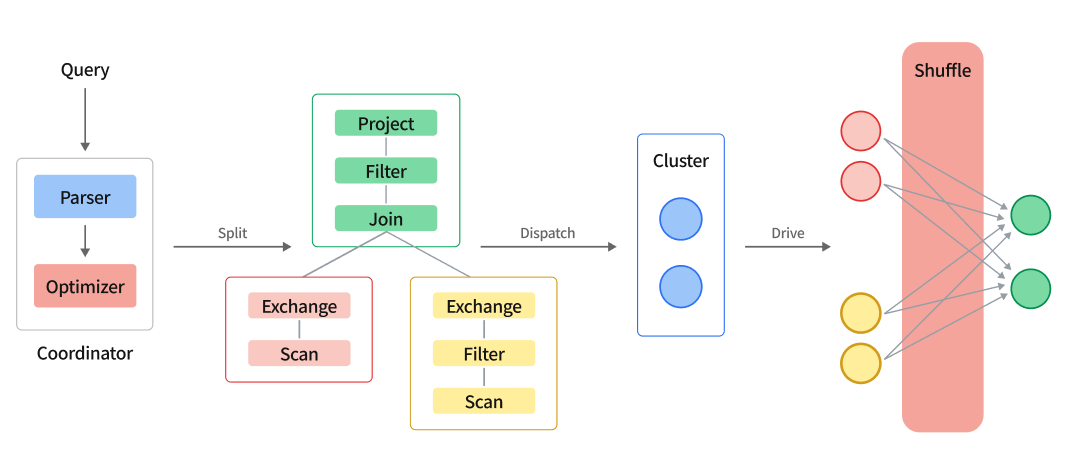
复杂查询执行模型图
复杂查询的执行流程如下:
- Query SQL String 通过 parser 解析为 AST
- 对 AST 做改写和优化,产生执行计划
- 启用优化器的时候,通过优化器产生执行计划。
- 将执行计划切分为多个 PlanSegment
- PlanSegment 即分布式执行过程中的一个执行片段,它包含
- 执行需要的 AST 片段,或者一个由 PlanNode 构成的逻辑执行计划片段
- PlanSegment 执行的节点信息
- PlanSegment 的上下游信息,这些信息包括上游的输入流,下游需要的输入流
- 引擎的调度器会将这些 PlanSegment 构成一个 DAG,然后按拓扑排序下发给集群中的所有节点
- 每个节点收到 PlanSegment 之后,开始驱动 PlanSegment 执行
- 包含数据源的 PlanSegment 开始读取数据,将数据按照一定的 shuffle 规则分发到下游的各个节点上
- 包含 exchange 输入的 PlanSegment 等待上游的数据,如果需要继续做 shuffle 则会继续将数据下发给各个节点
- 多轮 stage 完成之后,结果会返回到服务端
如何开启查询级别参数
开启优化器会自动走复杂查询执行模型。通过配置 enable_optimizer=1,或者 dialect_type='ANSI' 可以开启。
- 确定统计信息存在
没有统计信息,生成的查询计划不是最优。show stats [<db_name>.]<table_name>
- 分析计划每一个 Step 的耗时
通过 explain analyze sql 可以显示每一个 Step 的耗时
- 参数调优
ByteHouse 支持查询级别的参数调优,参数可以针对不同的查询分别进行设置。与 Exchange 算子相关的参数也可以通过这种方式进行设置,通过关键字SETTINGS 为查询指定参数值,如下所示:
SELECT 1 SETTINGS TEST_KNOB=1;
当执行此 SQL 语句时,参数 TEST_KNOB 将被强制设置为 1。以这种方式设置参数不会影响其他查询的参数值。
接下来,我们展示了一些对性能有重要影响的查询级别参数。
- Exchange 算子负责 PlanSegment 之间的数据传输。
exchange_source_pipeline_threads 影响 pipeline 执行的总线程数目,尤其是非 source 的 pipeline(指直接从存储读取数据的 pipeline),目前默认设置为 CPU 核数,目前并没有一个理想推荐值,可以考虑/2 或者*2 观察结果。如果查询内存占用较大,可以调小。
exchange_timeout_ms Exhange 超时时间(ms),默认为 100s,如果出现 Exchange 相关超时报错可以适当调大。
exchange_unordered_output_parallel_size 影响 Exchange 输出数据的并发能力,默认为 8,一般不需要调整。如果 exchange_source_pipeline_threads 调整比较大,可以适当调大 exchange_unordered_output_parallel_size,增加上游输出能力。
exchange_enable_block_compress 是否开启 Exchange 压缩,默认开启,如果 CPU 瓶颈比网络明显,可以尝试关闭。
exchange_parallel_size 决定了单分区数据向下游 shuffle 的分区数量,默认值为 1。通常情况下,无需调整此值。只有在未来需要对 Exchange 进行排序的场景中,才需要通过调整 exchange_parallel_size 来增加分区数量,以提高下游算子的并发处理能力。
exchange_local_receiver_queue_size 表示本地 exchange receiver 的队列大小。它通过算子的异步和算子状态的同步来实现软流控制。它向 Sender 发送两个信号,空闲和积压。Sender 会降低积压流的传输优先级,并提高空闲流的优先级。
exchange_remote_receiver_queue_size 表示远程 exchange receiver 的队列大小。
exchange_buffer_send_threshold_in_bytes 限制了 Exchange 刷新发送缓冲区时的最小字节数,它决定了 receiver 的积压阈值大小。
exchange_buffer_send_threshold_in_row 限制了 Exchange 刷新发送缓冲区时的最小行数,它决定了 receiver 的积压阈值大小。
- 有一些参数既可以对整个数据库生效,也可以对单个查询生效。
max_threads 限制了执行请求的最大线程数量。默认情况下,它是自动确定的。
max_block_size 限制了读取的最大块大小。默认情况下,它是 65536。
- 路由相关的参数通常用于确定分布式系统中数据的存储和访问路径。
group_by_two_level_threshold 表示从多少个键开始进行两级聚合。
group_by_two_level_threshold_bytes 表示从聚合状态达到多少字节时,开始使用两级聚合。
- runtime filter 旨在为某些连接查询在运行时动态生成过滤条件,以减少扫描的数据量,避免不必要的 I/O 和网络传输,从而加速查询。以下是一些与 runtime filter 相关的参数。
runtime_filter_min_filter_rows 限制了启用 runtime filter 的最小行数。
runtime_filter_bloom_build_threshold 限制了构建 bloom filter 的右表的阈值。